为什么分布式数据库要100%保证数据的正确性?
【CSDN 编者按】本文阐述一致领域存在诸多的问题,他们可以用“一致性24字问题”加以概括:范围不清、定义不明、多意、多词、理论有缺、扩展无法、系统难平。提出100%保证数据正确的必要性。
作者 | 李海翔 责编 | 夏萌
出品 | 那海蓝蓝知数行云
数据正确性的24字难题
数据库范围内,ACID中的C和I,是两个非常重要的特性,I表示并发执行的事务在执行过程中互不影响,即互相处于“隔离”状态,C要求并发执行的事务最终结果是正确的。
尽管C和I非常重要,但遗憾的是,传统的数据库知识从未把这他们的概念清晰表达,而是存在二义性(完整性约束和ACID之C的二义差异),并且缺乏用严谨的数学方式加以定义。
另外,更重要的是:没有直接把前述的数据异常和一致性的概念关联起来。在大众的头脑中,似乎数据异常和一致性有着很强的关系,但是没有从数学的角度把他们之间的关系完全掲示出来。
除了事务处理技术领域,谈及事务一致性外,还有其他领域,都在提及一致,如操作系统领域会涉及cache一致性、大型分布式缓冲软件系统会涉及缓冲一致性、CAP中的C也是在谈及一致性,这些不同领域的一致性有什么不同?他们之间的本质是否存在某种必然的联系?
事实上,一致领域存在诸多的问题,他们可以用“一致性24字问题”加以概括:
- 范围不清:是从整体上描述数据正确性问题存在边界不清晰的问题,如数据库的一致性和Cache一致性、分布式一致性等之间的边界模糊,这使得各个领域似乎都在解决一致性问题,但都各自为战,不能形成有效的统一的体系系统化地解决数据正确性问题。
- 定义不明:指每个领域内的一致性的定义是不明确的,缺乏形式化的表达,即缺乏科学的定义方式,这表明我们并没有深入理解其本质问题。
- 多意:在数据库中,一致性的含义有不同的内容,如完整性约束表达的一致性,有ACID的C表达的因并发操作同一对象导致的一致性,因此一致性这个词是存在多种解释的,这会使得学习数据库的人困惑不解。
- 多词:在数据库中,一致性和数据异常和数据正确性等,似乎存在着某种关系,但是却用了不同的词表达,且词与词之间的含义、关系是不明确的,这也会使得学习数据库的人困惑不解。根据文献[6]可推知,有冲突环图一定不一致性(有环是充分条件非必要条件);但不能知道不一致一定是有环(有三个数据异常游离于冲突环外,分别是:Dirty Read、Dirty Write、Intermediate Read);
- 理论有缺:事务一致性依赖的可串行化理论不完备;可串行化不能消除所有的数据异常;冲突可串行化也不能消除所有的数据异常(根据文献[6]需要处理如Dirty Read等特例)。
- 扩展无法:事务一致性和分布式一致性的关系不清晰,导致单机系统的数据正确性无法扩展到分布式系统中(目前只能依据经验解决而不能有明确的定义和规则):在分布式数据库系统中,CAP的C和ACID的C之间的关系是什么?“严格可串行化”是最严格的一致性语义,这个概念是结合了可串行化和线性一致性的语义而成的,适用于分布式事务型数据库系统;但分布式系统是否只存在“严格可串行化”这一种一致性?
- 系统难评:无论是单机还是分布式数据库,都缺乏一致性检测体系。Oracle数据库有可串行化隔离级别,但是在运行了若干年之后,被发现其所谓的可串行化隔离级别不能消除Write Skew数据异常,因此是一个假的数据异常;而其他的数据库系统,号称实现了可串行化,但是没有一个验证标准,可把数据库作为一个黑盒子进行一致性验证;数据库厂商提供不了数据正确性的评测方法,理论界也不能提供(参考“第三代分布式数据库(3)——一致性八仙图”关于“一致性八仙图”和Jepsen的讨论)。
相关概念混淆:无论是学术界还是工程界,因为一致性缺乏明确的定义,因此不同人对该概念有着不同的理解。有些词经常混淆在一起,如事务范围内容和ACID相关的一致性,分布式系统下和线性一致性、因果一致性等相关的分布式一致性,强一致性(多指多副本复制时被复制的数据与原始数据自己的一致性),最终一致性等。
一言以蔽之:乱!
从历史的角度看数据正确性
让我们沿着时间的轨迹来梳理人类对于数据异常的认知过程,感悟技术的进步与发展过程。
数据异常,至今尚没有明确的定义。业界对于数据异常,只有一个个具体的数据异常名称,每个数据异常对应一个形式化表达式。即过往对于数据异常的研究,止于具体的案例(如脏写、脏读、不可重复读、幻读等数据异常),且不能让人明白各种数据异常之间的关系。在事务处理领域,尚存在一些基本问题,如“数据异常究竟有多少个?数据异常之间的关系是什么?”是不为人所知晓的。
本节讨论数据异常的研究历史和其中存在的一些问题。在事务处理技术的发展历史上,不同人定义过不同的数据异常。
1. ANSI/ISO-SQL标准定义的数据异常
ANSI/ISO-SQL标准[7]定义了四种数据异常,分别是:脏写(Dirty Write)、脏读(Dirty Read)、不可重复读(Non-repeatable Read)和幻读(/Phantom)数据异常。
这四种数据异常,后文会另行介绍,在此不再赘述。
2. Jim Gray等定义的数据异常
数据异常,不只是ANSI/ISO-SQL标准所定义的四种,还有更多数据异常。Jim Gray等人在参考文献[6]中定义了八种数据异常,除了ANSI-SQL标准定义的四种外,新增加了丢失更新(Lost Update)、游标丢失更新(Cursor Lost Update)、读偏序(Read Skew)和写偏序(Write Skew)数据异常。
该参考文献给出的新的数据异常的形式化定义如表1所示。其中,丢失更新的定义存在难以理解之处。例如:
H1是丢失更新数据异常的形式化定义,但该定义中的“W2[x]...W1[x]”构成一个脏写异常,因此该形式化定义和脏写异常的定义冲突,不能判断该定义究竟应属于哪种数据异常。该文献对丢失更新举例如H2,其中“W2[x=120] C2 W1[x=130]”中存在有“C2”这使得该示例与脏写异常不存在冲突之处,因此其定义应该更新为H3。
游标丢失更新数据异常的定义类似丢失更新,出现在支持“游标(Cursor)”功能的数据库系统中,如DB2、Informix、MySQL、PostgreSQL等。
读偏序数据异常,其定义为H4。对于事务T1和T2,是两个事务作用在两个变量上,按照冲突可串行化理论,在变量x上形成RW冲突,在变量y上形成WR冲突。但是,为什么在“W2[y]...C2...R1[y]”中需要有“C2”存在呢?如果不采用读已提交规则,则完全可以存在H5的方式。所以,是否存在一种可能,使得H4和H5,都是读偏序异常呢?
写偏序数据异常的定义为H6。对于事务T1和T2,是两个事务作用在两个变量上,按照冲突可串行化理论,在变量x上形成RW冲突,在变量y上形成RW冲突,即该异常有两个RW冲突这点不同于读偏序异常的一个RW一个WR冲突。而该定义中“C1 and C2”位于表达式的最后,但是,H7中只是把“C1”提前到“W2[x]”,这样对于事务T2而言,无任何影响,所以是否我们可以认为,H6存在H7这样的等价变形形式?即是不是H6并没有把写偏序的定义完整表达?
表1 《A Critique of ANSI/ISO-SQL Isolation Levels》定义的新的数据异常
表13. 已知的数据异常与问题思考
前两节讨论了不同组织或学者发现并定义了不同个数的数据异常,ANSI/ISO-SQL标准定义了四种而Jim Gray等定义了八种,自然而然的,我们会产生这样一个疑问:究竟还有没有新的数据异常?
如表2,汇总了19种数据异常。该表的“异常名称”列还给出报告该异常的文献和文献发表的年份,可以看出,从1992年到2019年近三十年的时间里,不断有新的数据异常被报告。由此,我们会产生一系列疑问:究竟有多少种数据异常?数据异常之间,有什么必然联系?数据异常的命名,是不是也是有规律可循的?新的数据异常,应该在哪个隔离级别下被消除(即数据异常和隔离级别的关系,究竟是什么)?
表2中,“Cross-Phenomenon”数据异常,是四个事务作用在两个变量上构成的数据异常,这样的数据异常,为什么是“数据异常”?为什么该异常和其他的数据异常有不同?不同之处又在哪里?还有,上一节我们讨论了写偏序异常,而表2给出了一个称为“谓词写偏序(Predicate-Based Write Skew)”的数据异常,这两类数据异常看起来有些相似之处,都是两个事务在两个变量上存在两个RW冲突关系,但是后者的读操作带有谓词,那么,是否每一个带有读操作的数据异常都对应有一个谓词类数据异常?如果是这样,为什么到目前为止,只报告有幻读和谓词写偏序数据异常这两个谓词类的数据异常,而没有报告出更多的谓词类数据异常?
另外,表2中,第十个和第十一数据异常,表达式相同,但却是被不同的参考文献在不同的场景下报告得出:在2014参考文献[3]和2017年参考文献[1]报告的“fractured reads”是一个不区分分布式环境的数据异常,在2014年参考文献[2]报告的“Serial-Concurrent-Phenomenon”是一个分布式环境下的数据异常。根据这样的情况,我们可以思考,为什么同样的数据异常会被命名不同且数据异常?数据异常和分布式环境有着什么样的关系?
再如,表2中,大部分数据异常都是涉及单个变量的数据异常,而 “Read Skew”却有两个变量,这是为什么?根据这样的情况,我们可以思考,是否会有三个变量或更多变量的数据异常存在?数据异常和变量个数之间有着什么样的关系?
表2表明数据异常有很多个,他们都是一个个具体的案例,我们可以思考:如何对这些数据异常分类?是否可以从数据异常整体的角度,给数据异常一个简洁而统一的科学定义?
前述这些问题,表明数据异常的研究,尚不充分。这就需要我们对数据异常开展系统化的研究工作。参考文献[5]给出了如何对数据异常开展体系化研究的工作。
表2 已知数据异常汇总表[3]
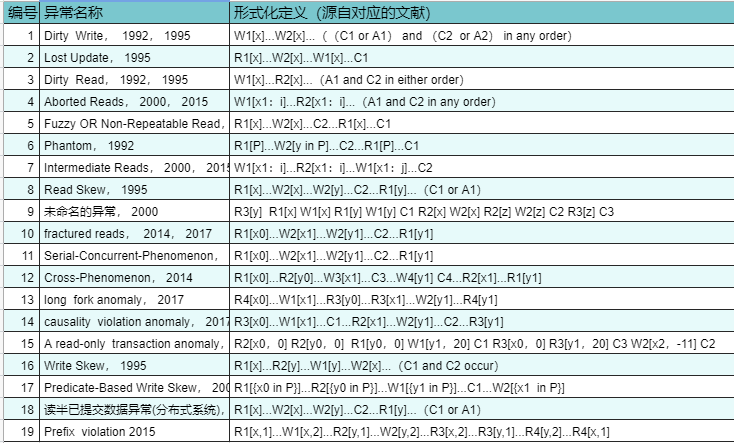
表2
4. 为什么会产生数据异常?
可串行化理论源自串行化的思路,直观地看,如果所有的事务都串行执行,则数据的一致性不会被破坏,即在单个事务的操作下,事务使得数据能够从一个初始的合法状态变迁为事务结束后的另一个合法状态。因此不会有数据异常发生。
而一个事务对数据的操作,抽象后无非是两种,读操作和写操作。如果有两个或两个以上的事务并发地操作相同的数据项,则存在四种组合情况,分别是读读、读写、写读和写写。其中,只有读读不会改变数据的状态,而其他三种组合都会改变数据的状态,因此存在出现数据异常的可能。但是,这并不意味着数据异常一定会出现。
例如,表2中的脏写定义如H8。该异常的定义中包括了事务的提交或回滚的状态,且“any order”表明T1和T2的提交或回滚的状态可以交换位置,因此存在表3中的八种情况。该表采用数据状态变迁方法,观察不同操作对数据状态的变迁变化,来观察数据一致性的保持情况,其中事务执行过程中允许数据处于不一致性的状态,但事务结束必须使得数据处于一致性状态。
H8 = W1[x]...W2[x]...((C1 or A1) and (C2 or A2) in any order)
表3中编号1到6的存在数据不一致的情况,但编号7和编号8实际上不存在数据不一致,但是“WW”却被定义为脏写,这不合理。或者说,为什么没有文献讨论脏写因何会被这样定义?作者的理解是,对于编号7和编号8的情况,因为都涉及了回滚操作,而这样的回滚操作是浪费计算资源的操作,与其允许其发生而浪费计算资源,倒不如禁止“WW”发生而节省计算资源为好,因此“WW”被直接定义为了数据异常。但是这样的定义方式,不利于理解“什么是数据异常”。
因此,我们提出疑问:究竟是什么原因使得数据异常产生?前述这些问题,不由得促使我们深思。
表3 “W1[x]...W2[x]”的事务状态展开的八种情况表

表3
从应用的角度理解数据正确性
数据库教科书,通常会抽象地、不完备地、且非数学方式不严谨地讲四个数据异常(ANSI-SQL标准定义的Dirty Write、Dirty Read、Non-repeatable Read、Phantom),读后会很容易“不理解”!
其实,结合实际的应用背景,可以很容易地理解数据异常。
1. 对账应用——对账错误
金融交易中,对账是一个重要的工作,通过对账,可知道“总账目应当是平衡的”。
这个事情,在数据库中,对应事务的示例如:
如图1所示(分布式环境下,一个被称为Serial-Concurrent-Phenomenon的异常),写事务正在执行从Na节点的X账户转账10元到Nb节点Y账户。当Na节点完成提交,而Nb节点尚未提交,此时,一个读事务的读操作,从Na节点读取到的是新值“X-10”,而从Bb节点读取到的是旧值“Y”,对账写事务之前的“X+Y”与读事务读到的“X-10+Y”,账户总账不平。
如果数据库系统的实现存在问题,单机系统下,该异常也能出现。
该异常本质上是“Write Skew Committed”类异常。
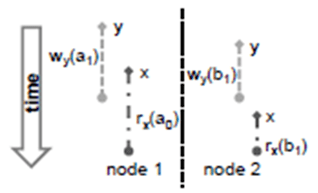
图1 Serial-Concurrent-Phenomenon示意图
2. 对账应用——对账不平
一个单位,有多位财会人员使用同一份数据对账,需要确保账结果是一样的,不能出现一个计算结果是5而另外一个是10的情况。
这个事情,在数据库中,对应事务的示例如:
如图2所示,两个分布式事务x和y并发执行,node1上局部事务s修改了数据项的值为a1后,子事务y读数据项的值为a1。而在node2节点上,与node1相似,局部事务t修改了数据项的值为b1后,只是子事务x读数据项的值为b1。所以事务x读取到的是(a0,b1)这样一个不一致状态的数据。同理,事务y读取到的是(a1,b0)这样一个不一致状态的数据
在实际应用中,账户对账业务,如果并发访问控制算法处理不当,则会发生这种数据异常。例如,事务x和y分别是两个对账人员同时进行对账,但是他们的对账结果却不同,这样的差异会令人费解。
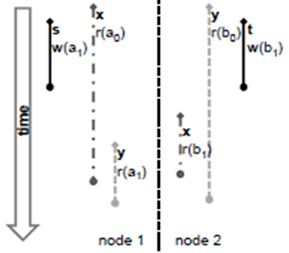
图2 Cross-Phenomenon示意图
3. 电子交易——记账错误
有一类数据异常,称为“Write Skew”。其表达式可简写为:
R1[x0] R2[y0] W1[y1] W2[x1]
Jim Gray在提出该异常时,给定的意义是:假设x和y满足某种完整性约束,如x+y=0,那么修改之后的x和y,仍需满足该完整性约束。
在电子交易中,如银行的应用,有场景与此对应。
假设允许一个人的总账户下有两个子账户,每个子账户可各自进行存款和取款业务,但要求总账户上的存款余额必须大于等于零,即不允许透支。
如果使用该两个子账户取款,则存在透支风险。
假设两个子账户各自有存款x=10、y=20元,而各自取款30元(符合总账户不透支的要求),如果串行执行取款,则最多能取到30元,这是符合要求的;如果并发执行,则最多能取出60元,透支了30元,违反了完整性约束。因此该类数据异常需要在电子交易场景中消除。
4. 其他数据异常的现实意义
如Dirty Read,如果读取了其他事务未提交的写操作的结果,采用该结果进行计算,则容易出现错误:错误发生在该“其他事务”回滚,其所写的结果就是一个不可能存在的结果,基于不可能存在的结果发生的读之后的计算则必然错误。如图3,是事务T2读取了一个事务T1临时生成的值,之后事务T1回滚致使该值在数据库中不存在,对于事务T2而言,会读到“未曾真实存在过的、临时的一种数据状态”因而是一种“异常”。该异常的特点,是事务T1的回滚操作,影响了T2曾经读到的数据;即回滚操作会对数据异常构成影响。
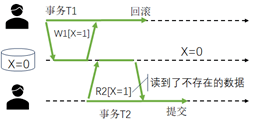
图3 脏读数据异常
Dirty Write未必会导致数据不一致,如交易类应用,记账时,分别给同一个元组的库存字段减去两次的交易量并都成功,则X-Y-Z和(X-Y)-Z的结果是一样的。但如果前一个写事务失败回滚,另外一个即需要分情况特殊处理才能确保最终结果符合A(原子性)和C(一致性)。
例如,两个事务(T1、T2)各自写了相同的数据项(row),T2事务覆盖了T1事务所写的值。但是,这么解释,有些牵强,因为存在一种情况是“W1[x0] C1 W2[x1]”事务T2的写操作同样覆盖了事务T1的写操作,这样算不算是脏写数据异常呢?很多数据库系统如PostgreSQL、Oracle等并不把“W1[x0] W2[x1]”作为脏写异常而处理,这是实践层面和ANSI-SQL标准脱节之处(也是和理论脱节之处)。
Non-repeatable Read/Phantom使得了本事务前后两次读到的数据不同,计算结果可能出现错误。如图4,是事务T2所写的值,被事务T1在T2写之前和写之后各自读了一次,但两次所读到的结果不同,结果不同导致“前后逻辑不一致”所以是一种“异常”。该异常的特点,表明两个并发事务的操作有交叉会构成数据异常。
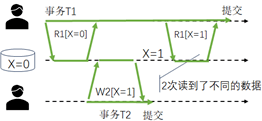
图4 不可重复读数据异常
幻读数据异常,如图5所示,类似不可重复读异常,只是读取数据时,不是直接操作某个实体数据项,而是通过谓词进行读或写。该异常的特点,是读操作中带有了谓词,而谓词源自用户发出的SQL语句中的WHERE子句对应的条件,即谓词会对数据异常构成影响。但是,数据库界对于幻读异常认知不同,如下是ANSI/ISO-SQL标准(P3)和Jim Gray(A3)等对于幻读的定义。Jim Gray等定义认为前后两次相同的读操作,得到的结果集不同,第二个读操作的结果集因之前的写操作新加入数据项而被改变。从下面的形式化表达式中可知,A3比P3严格很多,P3是一种粗放式的定义,只要发生带谓词的读以及之后发生一个其他事务的符合谓词范围的写操作,则发生幻读,这是一种扩大了防范范围的定义方式,如果后面不发生第一个事务带谓词的读操作,实际上不会发生幻读,所以A3的定义方式更为严谨一些。但是,A3中的提交操作即c2是必须的吗?这个问题没有被深入研究而讨论过,这表明A3的定义其实并不严谨。换句话说,有必要深入研究,数据异常究竟应该怎么严谨地定义?
P3:r1[P]...w2[y in P]...(c1 or a1) (ANSI/ISO-SQL标准定义的Phantom)
A3:r1[P]...w2[y in P]...c2...r1[P]...c1 (Jim Gray等定义的Phantom)
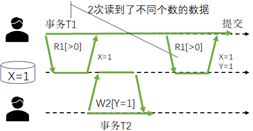
图5 幻读数据异常
Lost Update使得用一个合法的更新过的值不存在而不能被读取到,从而丢失了正常的正确的记账结果。
Write Skew互相破坏了对方数据在读取数据前保持的一致性,因此用两个互不一致的状态参与计算,致使计算结果有误。
其实,不只是有这些异常现象,在论文《数据库管理系统中数据异常体系化定义与分类》(本文的内容基于该文,请先阅读该论文)中系统总结了各种不同一致的数据异常现象,读者可详细参考。
数据异常的新发展
继ANSI/ISO-SQL标准定义了四种数据异常和Jim Gray定义了八种数据异常之后,Andy通过定义隔离级别也对数据异常进行定义(采用两种方式,一是基于冲突图定义环来定义数据异常,二是把几个“不能纳入环方式定义数据异常”的几个情况作为特例加以定义)。
之后,如表2所示,从二十世纪的九十年代到二十一世纪的二十年代,三十多年间,不同的参考文献分别零星的发现、定义了十几个不同的数据异常,这使得数据异常的数目发生了变化,进一步扩展了人类对于数据异常的认知。众多的数据异常虽然被不断报告,但是没有引发人类对于数据异常的系统化思考,比如,存在的问题有:究竟有多少个数据异常?十几个已知的数据异常之间有什么关系?这十几个数据异常怎么对应到ANSI/ISO-SQL标准定义的四个隔离级别下?同理,这十几个数据异常怎么对应到Jim Gray定义的六个隔离级别下?数据异常究竟有什么价值?
再之后,进入二十一世纪,参考文献《数据库管理系统中数据异常体系化定义与分类》系统地对数据异常进行梳理和思考,通过形式化的方法,尝试定义所有的数据异常,并试图研究数据异常的本质和对事务处理技术的影响,这使得对数据异常的研究进入一个新的阶段。
更进一步信息可参考文献《数据库管理系统中数据异常体系化定义与分类》(http://www.jos.org.cn/jos/article/pdf/6442)或者《硬核干货 | 数据异常的本质和价值详解》(https://www.modb.pro/db/168385)。
为什么要100%保证数据正确性?
请思考几个问题:
- 您能说出多少个数据异常?教科书能说出多少个数据异常?
- 有谁能说出哪些数据异常在哪些场景中会出现?从而能指导你在应用开发中去避免数据不一致性现象?
- 有谁能说清楚数据异常和隔离级别的关系?
- 有谁能说出数据异常和数据库系统的性能的关系?
如果您不能回答这些问题,请问数据异常是否为您的基于数据库的应用开发带来了心智负担?是否您会担心数据的不一致性现象?
如果我们不想迷失在“一致性的迷雾”中,如果我们想清晰地认知数据正确性,如果我们不想基于数据库的应用存在任何心理负担(担心数据不一致),如果我们想在数据正确性方面永远高枕无忧,那么,100%确保数据正确性,是非常必要的。
另外,在100%保证数据正确性的同时,可得到最大化的并发性能。鱼和熊掌可兼得。这一点,是可证明的。
换句话说,隔离级别是无用的,只保留可串行化隔离级别即可(未来进一步探讨可串行化隔离级别存在的问题)。
参考文献
[1] Andrea Cerone, Alexey Gotsman, and Hongseok Yang. Algebraic laws for weak consistency. International Conference on Concurrency Theory (CONCUR 2017), LIPICS 85, pages 26:1-26:18, 2017.
[2] Lamport L, Shostak R, Pease M. The Byzantine generals problem[J]. ACM Transactions on Programming Languages and Systems (TOPLAS), 1982,4(3):382-401
[3] P. Bailis, A. Fekete, J. M. Hellerstein, A. Ghodsi, and I. Stoica, “Scalable atomic visibility with ramp transactions,” in SIGMOD, 2014, pp. 27–38.
[4] Hal Berenson, Philip A. Bernstein, Jim Gray, Jim Melton, Elizabeth J. O'Neil, Patrick E. O'Neil:A Critique of ANSI/ISO-SQL Isolation Levels. SIGMOD Conference 1995:1-10
[5] 李海翔,李晓燕,刘畅,杜小勇,卢卫,潘安群.数据库管理系统中数据异常体系化定义与分类.软件学报,2022,33(3):0
[6] A. Adya, B. Liskov, and P. O’Neil. Generalized isolation level definitions. In Proceedings of the 16th International Conference on Data Engineering, ICDE ’00, pages 67–78, Washington, DC, USA, 2000. IEEE Computer Society.
[7] ANSI X3.135-1992, American National Standard for Information Systems – Database Language – SQL, Nov 1992.
作者简介
李海翔,前腾讯、字节跳动等数据库首席架构师,中国人民大学、北京林业大学硕士企业导师,CCF大数据、数据库专委会执行委员,北京市、深圳市科技进步一等奖得主。著有《数据库查询优化器的艺术》《数据库事务处理的艺术》《分布式数据库原理、架构和实践》等。申请与授权专利100+,SIGMOD、VLDB等大会发表论文若干篇,参与国家863重大专项、核高基等多项目研发。
本文经授权转载自微信公众号「那海蓝蓝知数行云」,如需转载,请联系对方授权。
▶做瑜伽、分类物品,特斯拉“擎天柱”人形机器人再进化,Get 新技能!
▶【专属福利】全球云原生技术顶会即将开幕!
▶中国首个接入大模型的 Linux 操作系统来了