微软AR/VR专利分享用于虚拟表示的并行人体姿态估计
(映维网Nweon 2023年11月13日)关于人类用户姿势的信息可以映射到虚拟铰接表示。例如,当参与虚拟现实环境时,人类用户在虚拟环境中的表现会呈现出与现实世界姿势相似的姿势。用户的真实世界姿态可以通过先前训练的模型转换为虚拟铰接表示的姿态,模型可以训练为输出用于最终渲染的相同虚拟铰接表示姿态。
但有时候,系统可能需要显示远非真实的表示。例如,用户可以选择具有不同身体比例、骨骼和/或其他方面的不同卡通角色。
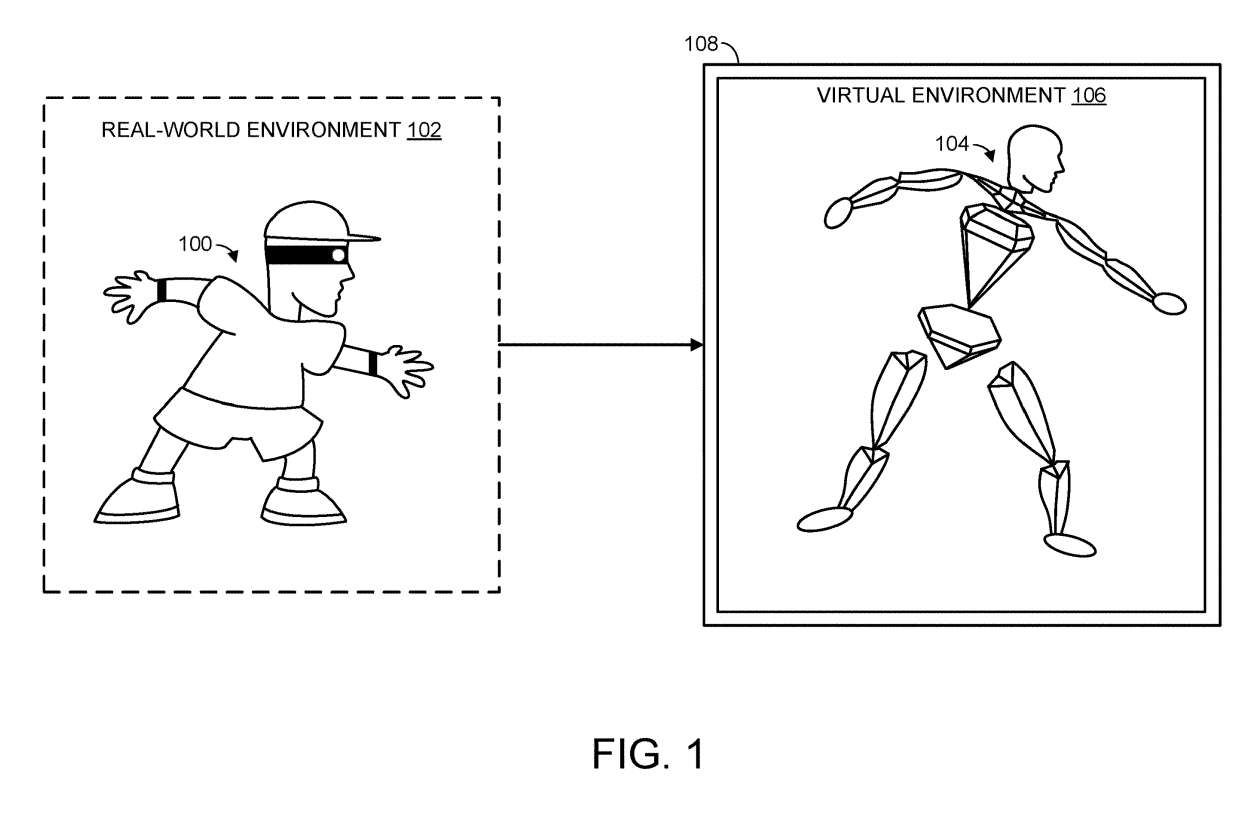
图1显示了真实世界环境102中的人类用户100。如图所示,将人类用户的姿势应用于铰接表示104。换句话说,当人类用户在真实世界环境中活动,相关活动将转换为虚拟环境106中铰接表示104的相应运动。
然而,有时候虚拟铰接表示可能需要与用于训练模型的表示不同。为了解决这个问题,名为“Concurrent human pose estimates for virtual representation”的微软专利介绍了用于同时估计模型铰接表示和目标铰接表示的姿态的技术。
具体地说,计算系统至少部分地基于来自一个或多个传感器的输入接收人类用户的一个或多个身体部位的详细参数的定位数据。这可以包括头显惯性测量单元输出,以及来自合适摄像头(例的输出。
系统同时维护一个或多个将模型关节表示与目标关节表示相关联的映射约束,例如关节映射约束。至少部分基于定位数据和映射约束,姿态优化机同时估计模型关节表示的模型姿态和目标关节表示的目标姿态。一旦进行了估计,就可以将目标关节表示与目标姿势一起显示为人类用户的虚拟表示。
姿态优化机可以使用具有用于模型铰接表示的ground truth标签的训练定位数据进行训练。然而,训练定位数据可能缺乏目标铰接表示的ground truth标签。
以这种方式,发明描述的技术可以有益地允许人类用户真实世界姿态的准确再现,而不需要为每个不同的可能目标铰接表示进行计算昂贵的训练。
例如当参与虚拟环境时,用户能够从虚拟环境中用于代表他们的各种不同的Avatar中进行选择,并且用户可以在会话期间动态改变外观。可以将新的目标铰接表示添加到用户可用的表示菜单中,而无需为特定表示重新训练模型的计算费用。
发明描述的技术可以提供减少计算资源消耗的技术优势,同时准确地重新创建人类用户的真实世界姿势,并允许将准确的姿势应用于多个不同目标铰接表示中的任何一个。具体方法是通过同时估计目标和模型的姿势。
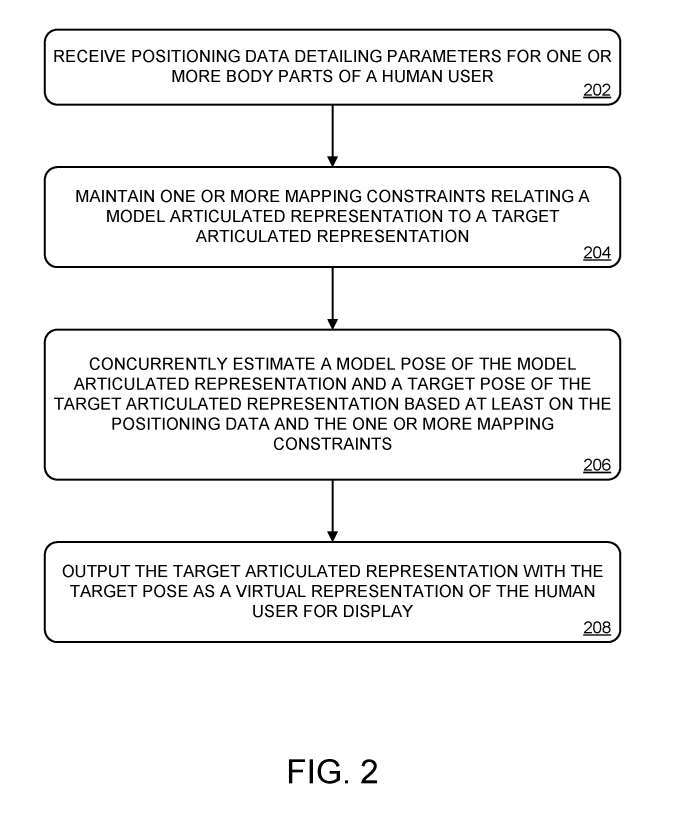
图2示出用于虚拟表示人体姿势的示例方法200。
在202,基于来自一个或多个传感器的输入,接收人类用户的一个或多个身体部位的详细参数的定位数据。
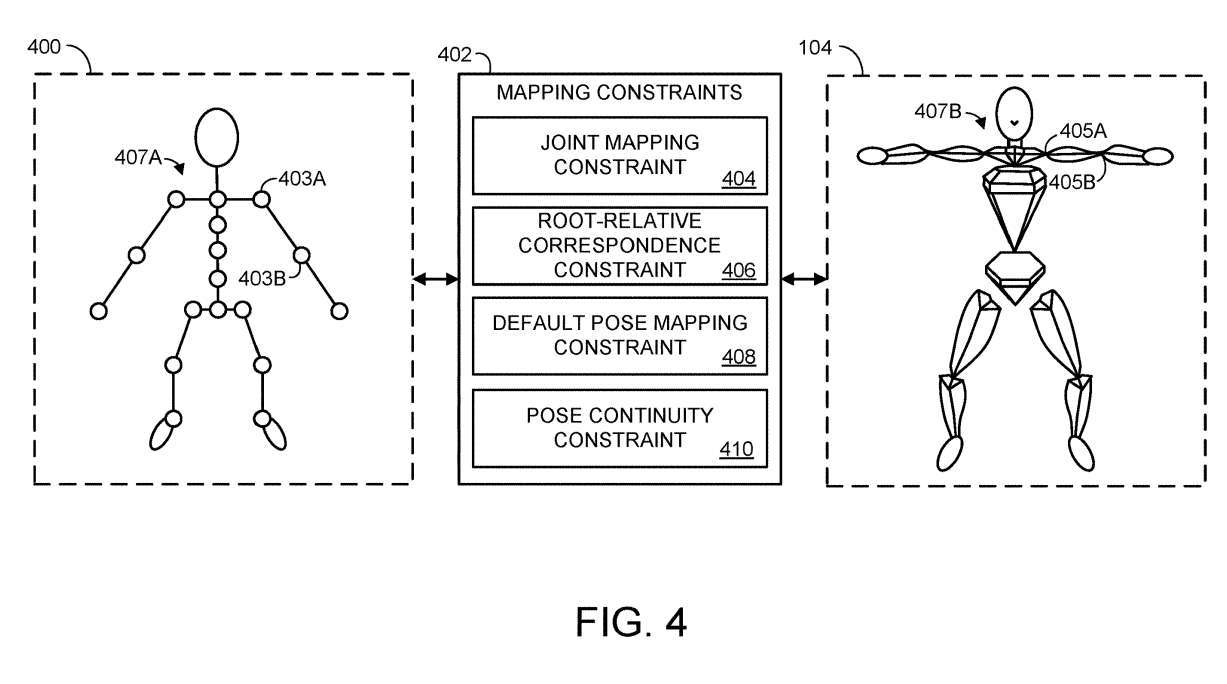
在204,维护一个或多个将模型铰接表示与目标铰接表示相关的映射约束。图4显示了示例模型铰接表示400。
如上所述,目标铰接表示呈现用于在虚拟环境中显示,并且可以通过姿态优化机输出目标姿态来显示。例如,目标铰接表示可以具有任何合适的外观和比例,并且可以具有任何合适数量的肢体、关节和/或其他可移动的身体部位。
目标铰接表示可以类似于非人类动物、虚构角色或任何合适的Avatar。模型铰接表示和目标铰接表示通过一个或多个映射约束402相关联。
一个或多个映射约束可以包括联合映射约束404。对于目标铰接表示的关节,关节映射约束指定模型铰接表示中的一组一个或多个关节。例如,模型铰接表示400包括多个关节,其中两个标记为403A和403B,其对应于肩关节和肘关节。
目标铰接表示104包括类似的关节405A和405B。因此,多个映射约束可以包括目标表示的关节405A和405B的不同的关节映射约束,表明关节映射到模型表示的关节403A和403B。
关节映射约束可以进一步指定映射到目标关节表示的关节的模型关节表示中的每个关节的权重。例如,当模型铰接表示中只有一个关节映射到目标铰接表示的特定关节时,模型关节的权重可能为100%。当两个模型关节映射到目标关节时,两个模型关节的权重可以是50%和50%、30%和70%、10%和90%等。
回到图2,在206,方法200包括通过先前训练的位姿优化机器同时估计模型铰接表示的模型位姿和目标铰接表示的目标位姿。模型位姿和目标位姿至少部分基于定位数据进行估计。
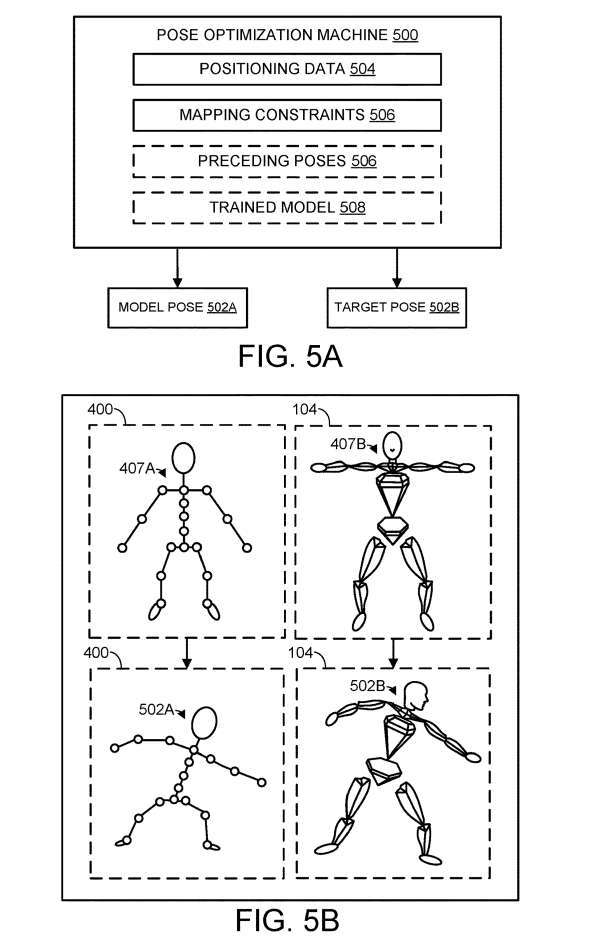
图5A示意性地示出了位姿优化机500的示例,其可以作为计算机逻辑组件的任何合适组合来实现。作为一个非限制性示例,位姿优化机500可以实现为如图6所述的逻辑子系统602。
如图5A所示,姿态优化机同时估计模型铰接表示的模型姿态502A和目标铰接表示的目标姿态502B。这至少部分地基于定位数据504和一个或多个映射约束506来完成。
姿态估计可以至少部分地基于在一个或多个先前时间框架估计的一个或多个先前模型姿态和先前目标姿态来完成。因此,位姿优化机器500存储多个先前的位姿506,其可以表示为每个模型关节的多个局部旋转。
一个或多个映射约束可以包括位姿连续性约束,它施加帧对帧的限制,限制给定关节的局部旋转可以从一个帧改变到另一个帧的程度。
图5B示意性地说明了将估计的模型和目标姿态应用于模型和目标铰接表示。具体而言,图5B再次描绘了模型铰接表示400和目标铰接表示104对应的默认姿态407A和407B。然后改变铰接定向的姿态,使得模型铰接表示400假设模型姿态502A,目标铰接表示104假设目标姿态502B。
应当理解,模型位姿和目标位姿是同时估计。换句话说,与替代方法相比,姿态优化机不首先为模型铰接表示输出模型姿态,然后将姿态转移到目标铰接表示。相反,姿态估计可以描述为同时为满足一组约束的两种不同表示找到两种不同的姿态。
例如,模型铰接表示的姿态可以受到姿态优化机器的先前训练的约束,以输出给定一组定位数据的可能的人类姿态,并且目标铰接表示的姿态可以受到将目标铰接表示与模型铰接表示相关联的一个或多个映射约束的约束。
另外,姿态估计可以由姿态优化机实现的先前训练的机器学习模型508执行。在一个实施例中,姿态优化机可配置为基于稀疏输入定位数据输出姿态。换句话说,姿态优化机可以训练成基于比姿态优化机在运行时通常接收到的更多的输入参数输出姿态估计。
换句话说,提供给姿态优化机的定位数据可能包含人类用户n个关节的旋转参数,而姿态优化机之前训练的是接收n+m个关节的旋转参数作为输入,其中m>1。然后,估计模型姿态可包括估计模型铰接表示的n+m模型关节的旋转参数,至少基于n个关节的旋转参数,而不基于m个关节的旋转参数。
另外,姿态优化机的训练定位数据可以不包括目标铰接表示的ground truth标签。相反,标铰接表示通过一个或多个映射约束与模型铰接表示相关,而映射约束通常将目标姿态约束为与模型姿态基本相似。
微软指出,采用上述技术,过程的速度可以有益地提高两个数量级。这可以实现模型和目标姿态的实时并发估计,而无需使用专门的硬件加速。
回到图2,在208,方法200包括将具有目标姿态的目标铰接表示作为人类用户的虚拟表示输出以供显示。例如在图1中,目标铰接表示104通过电子显示设备108呈现。表示目标铰接表示的显示装置可以采用任何合适的形式并且可以使用任何合适的底层显示技术。
相关专利:Microsoft Patent | Concurrent human pose estimates for virtual representation
名为“Concurrent human pose estimates for virtual representation”的微软专利申请最初在2022年4月提交,并在日前由美国专利商标局公布。