15T算力实现高速NOA,科大讯飞也要当智驾普及者?
今年8月份,我看了一个关于24节气之处暑的视频,文案大气得体,配音不仅发音标准、音色圆润而且对于朗读的节奏和抑扬都处理得十分得当。
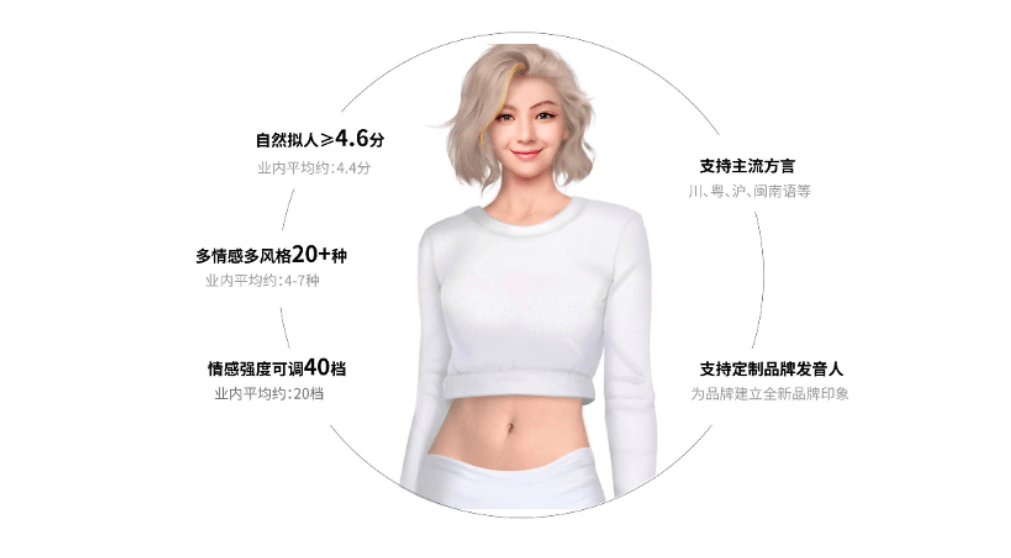
而这位优秀的朗诵者,居然是位AI。视频内注明了:文案来自讯飞星火V2.0,配音来自Smart- TTS。
对大模型感兴趣的朋友应该对此不太陌生,讯飞星火是科大讯飞在今年5月发布的认知大模型,而Smart TTS是用语音合成技术打造的情感化发音人,其形象、风格都可以按需调整。
在发布大模型时科大讯飞表示要在半年内对标ChatGPT,有信心实现“智能涌现”,当时很多人都嗤之以鼻,然而半年过去,其表现却出人意料。
昨天科大讯飞正式发布星火认知大模型V3.0,并基于此推出了智能汽车座舱、音效和智驾三大方向的产品升级。

首先是座舱方向,分为星火座舱OS、星火汽车APP和星火座舱域控,前两者是支持功能运转,后者则是为车企提供自主可控、更加开放的合作形式。
简单来说,通过大模型赋能,座舱就可以发挥出科大讯飞智能语音、自然语言理解这两项核心技术的优势,并且新增了实时检索能力,这样就可以理解需求并以百科全书式的知识储备去满足需求。
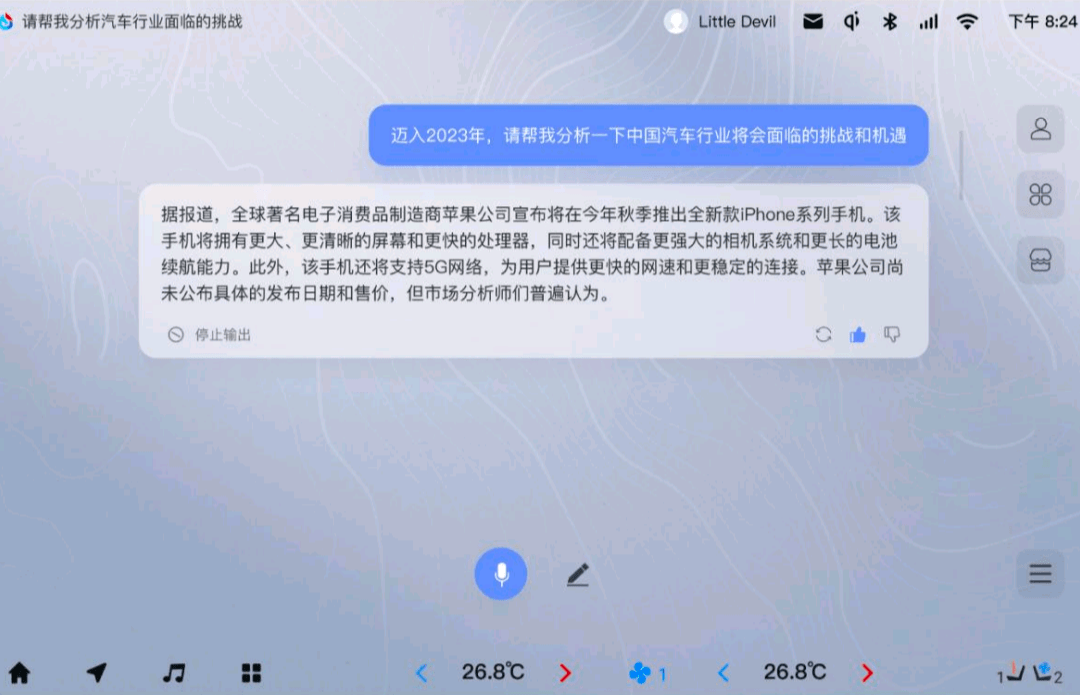
坐进星火座舱,星火汽车助理会通过语音交互的方式串联所有用车需求:
1.它可以理解指令的意图,完成任务。比如回答天气情况、打开空调等等。
2.知识实时更新加载。比如为车主介绍上海东方明珠的历史。
3.多轮交互,自动承接上下文理解。当我听完东方明珠的历史,表示我要去这里。星火助理就可以导航去东方明珠,而不是问我“这里是哪里?”
4.规划能力。比如我表示需要一份上海的旅游攻略,星火助理会主动询问人数、预算、时间,给出一份包括景点、餐厅、酒店的规划书,个别处不满意的话也可以手动更改。
5.创作能力。可以进行内容创作,比如以某句话开头写一个故事。
6.多风格交互。可以用不同角色的声音状态进行交互。
除了语音,座舱还深度融合了视觉模态,通过DMS系统对驾驶员进行疲劳监测、生理监测(心率等数据)等;通过OMS实现手势交互,比如用OK手势打开空调;通过多模态识别进行车主ID认证以及识别车主情绪。
星火汽车APP则是围绕用车场景打造的大模型车端应用,如用车顾问、儿童故事、口语陪练、心灵SPA、旅行伙伴等等,将大模型能力赋于众多实用场景。

接下来是音效方面,科大讯飞发布了最新的iFlySound Plus24ch功放硬件平台。科大讯飞在保证性能的前提下有效降低了硬件的尺寸和重量,实现“小型化轻量化”。
在软件算法层面,通过自主研发,当前已具备3D环绕、声场分区、响度补偿、主动降噪、虚拟音效、车载K歌和大模型音效等多个全自研的高阶音效算法。
在调音层面:大模型与车辆间的数据传达和下发调整、大模型和人工间的数据上传对比和参数配置建议以及人工对车辆音效的主观听感评测和直接要求调整参数,通过这样的闭环实现AI调音。

基于讯飞星火认知大模型,科大讯飞还带来了两款高性价比智驾解决方案——智驾STD和智驾PRO。
STD方案算力在15+TOPS,通过5颗毫米波雷达6颗摄像头的硬件组合实现包括高速NOA、自动泊车、确认式变道等功能。

PRO方案算力在50+TOPS,通过5颗毫米波雷达11颗摄像头的硬件组合实现包括增强型高速NOA、确认式变道、记忆行车灯功能。
如果搭载了智驾方案,那么在车外就可以通过语音让车自行泊入泊出。

可以看出,科大讯飞坚持了计算机视觉路线。有了大模型的加持,通过统一的BEV+Transformer网络,可以实现多模态、多任务、长时序4D感知,以低成本实现视觉智驾方案。
值得一提的是,在发布过程中,科大讯飞好几次提及Mobileye,作为同以计算机视觉技术为核心且入局量产智驾市场的科技公司,未来的竞争不可避免。
从配置上来说,科大讯飞推出的智驾方案再一次印证了市场的降本趋势。
同时这也和大模型的特殊性有关:大家对于大模型的付费意愿相对来说偏低,但把能力细分到各个场景,那么就可以通过互动变成个人离不开的“养成系”工具。
秉着“普及”的态度,科大讯飞表示所有产品都支持解耦式合作。随着百模大战的推进,大模型➕智能汽车领域将成为新的红海。