农业银行湖仓一体实时数仓建设探索实践
一、引言
在数字化转型驱动下,实时化需求日益成为金融业数据应用新常态。传统离线数仓“T+N”数据供给模式,难于满足“T+0”等高时效场景需求;依托Storm、Spark Streaming、Flink等实时计算框架提供“端到端”的实时加工模式,无法沉淀实时数据资产,存在实时数据复用性低、烟囱式垂直建设等不足。
为此,可通过建设实时数仓解决上述问题,实时数仓在离线数仓基础上进一步满足时效性的要求,依托流批一体、湖仓一体、云计算等技术,兼具时效性和灵活性优势,可作为金融业实时数据的生产、存储和使用平台。
为解决传统数仓数据时效性低等问题,实时数仓在技术路线上有多种路径:
一种是基于Lambda架构的实时数仓,作为当前主流实时数仓架构,其在现有成熟离线加工链路上,增加实时计算链路,参照ODS、DWD、DWS等模型分层组织理念,实现与离线数仓的协同,通常采用Kafka消息队列、Flink计算引擎等组合实现,建设成本较低,但架构复杂,运维成本较高;
一种是基于Kappa架构的实时数仓,与Lambda架构相比,其移除了离线生产链路,完全依赖实时加工链路,其优点是数据来源统一,架构相对简化,节约开发及日常运维成本,但不易进行数据回溯计算,比较消耗内存计算资源;
此外,还有一类采用实时OLAP技术,将聚合分析计算由OLAP引擎承担,减轻实时计算部分的聚合处理压力,分析自由度高,减轻了计算引擎的处理压力,但对引擎的吞吐、存储和实时摄入、分析性能要求较高,此类实时数仓通常基于商业数据库产品,如Hologres、GaussDB等。
同时,随着Hudi、Iceberg、Delta Lake等数据湖技术发展,依托数据湖底座的湖仓一体实时数仓建设正在兴起,对推进企业数字化转型具有重要价值:
一是弥补现有架构的不足,湖仓一体实时数仓弥补了传统数仓对于数据实时处理能力的不足,具备多引擎、多类型数据处理能力,流批一体加工类型丰富,避免了传统数仓无法分析非结构化数据等问题。
二是降低企业成本,湖仓一体实时数仓提供统一流批数据底座,避免不同平台间数据移动,降低数据流动带来的开发成本及计算存储开销,提升企业效率。
三是提升企业级数据分析整合能力,湖仓一体实时数仓打破了数据湖与数据仓库割裂的体系,将数据湖的灵活性、数据多样性以及丰富的生态与数据仓库的企业级数据分析能力进行了融合。
二、实时数仓建设思路
自农业银行大数据平台建设以来,经过多年的不断发展,沉淀了丰富的离线数仓模型资产,具备PB级数据存储和处理能力,支撑数百个应用场景。但总体来看,当前数据服务供给时效仍以T+N天为主,虽然依托实时流计算平台支撑了实时存款大屏等高时效应用,但“端到端”的流加工模式难于实现实时数据资产沉淀和复用。
实时数仓基于数据湖技术能力,支持构建稳定、全面、高扩展性的实时数据基础层,建设和沉淀农行共性实时数据资产,满足不同实时分析应用用数要求,提升数据模型加工时效性(见下图),结合Flink、Hudi等数据湖存储计算引擎,支持流数据、文件等数据入湖,利用Flink流批一体计算引擎层次化组织企业级实时资产,促进全行实时分析应用的统一。
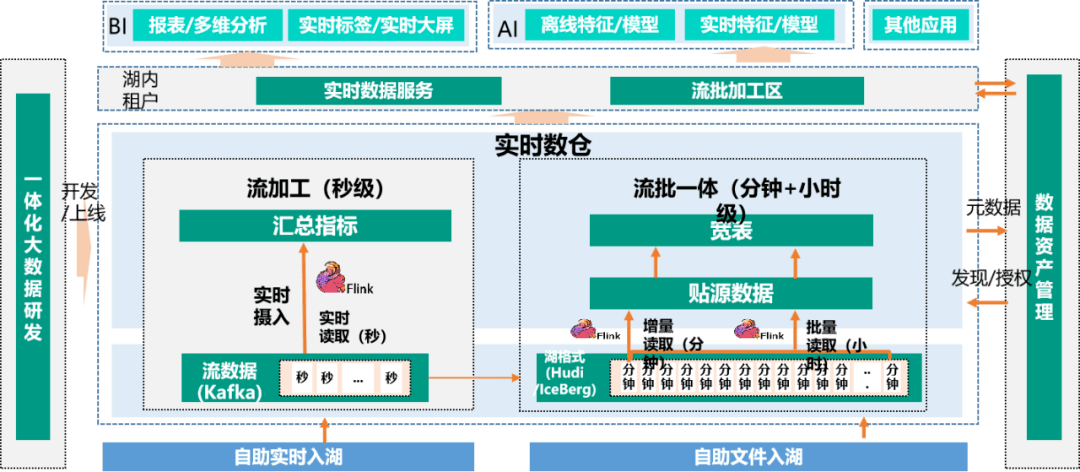
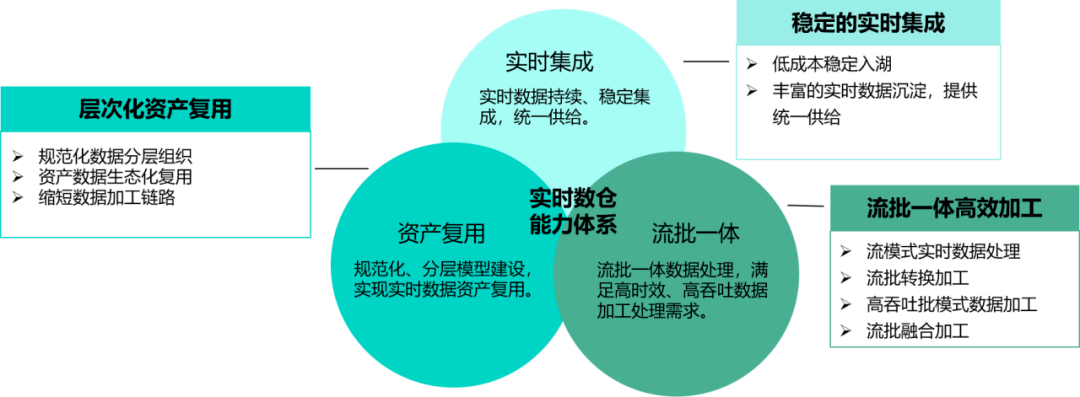
相比前期的实时流计算平台,它具有面向主题、有集成性、相对稳定等的数据仓库本身的特性,提供稳定、持续的实时数据统一集成能力,支持共性、个性层次化实时数据模型的构建,满足不同类型应用对流批数据加工模式的痛点需求。
为了提升实时数据资产的复用性,支持不同的应用,实时数仓采用数据分层理念组织实时数据资产。同时,考虑到层次增加会提高数据处理成本和时延,为缩短加工链路,实时数仓资产组织为ODS、DWD、DWS,外加DIM层。
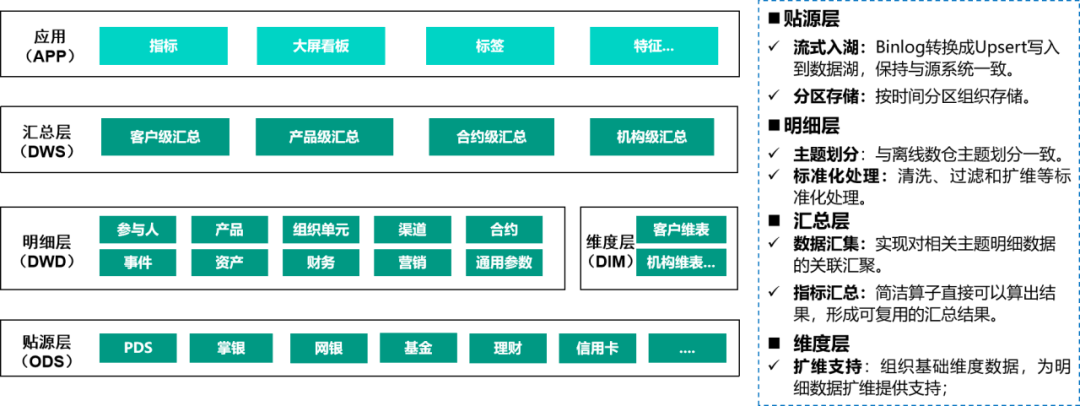
- lODS层
基于Hudi存储原始数据,Binlog日志消息转换成Upsert流式入湖,数据与生产源系统数据保持一致,保持原子粒度的数据。
- lDWD层
和离线数仓中DWD层主题划分一致,主要是为了解决一些原始数据中存在的噪声、数据不完整和数据格式不一致的问题,形成规范、统一的数据源。DWD层包括数据解析、业务整合、脏数据的清洗和模型规范化。
- lDIM层
DIM层是实时数仓中的维度数据,主要分为2类:变化频率低的和变化频率高的维度数据。对于变化频率较低的维度数据,比如说机构信息等,可以通过离线维度数据同步到缓存或者通过公共维度服务进行查询;对于变化频率较高的维度数据,比如说汇率、价格等信息,则需要监听其变化情况,维护变动信息。
- lDWS层
DWS层即汇总层,主要是对共性指标的统一加工,同时根据主题进行多维度的汇总等操作。特别地,对于时间区间的汇总,可以使用Flink中丰富的时间窗口实现。
三、实时数仓建设关键技术
1.实时数据入湖
实时数据入湖是湖仓一体实时数仓数据模型建设的基础,与流计算模式下“即用即弃”的数据处理策略不同,湖仓一体实时数仓借助Hudi数据湖存储引擎对实时流数据进行摄入存储,以支持流读、批读等流批一体处理。为了支持实时数据Upsert语义,并提供ACID事务保证,实时入湖环节会带来较高的处理开销,因此为了保障大规模实时数据持续稳定入湖集成,该环节对Hudi表类型、压缩机制、Flink checkpoint间隔设置等有较高要求。
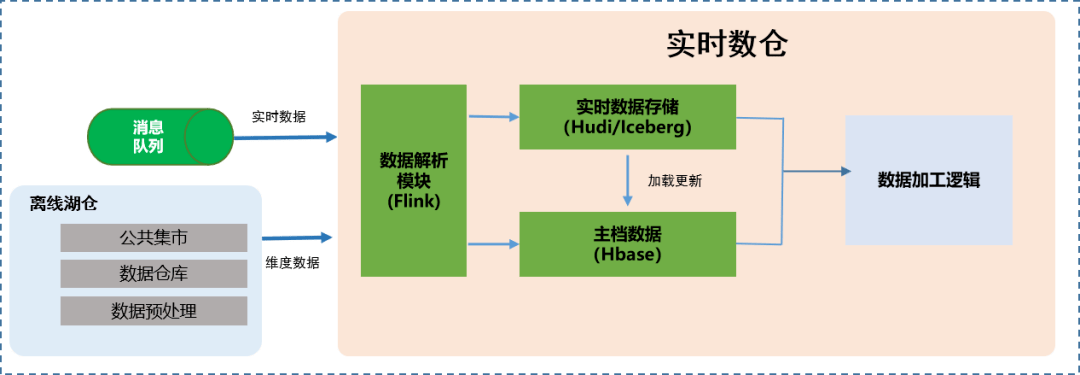
实时入湖表类型选取方面,根据读写特性的不同,Hudi表类型区分为MOR(Merge On Read)、COW(Copy On Write)模式。MOR方式通过不断追加日志,在读取时进行合并,适用于高吞吐写入场景;COW方式是在写入就进行合并操作,适合快速读取场景。为保障农行高吞吐实时交易等数据入湖,对于个人活期交易明细等大表优先选择MOR方式。
入湖过程中持续的并发写入,容易导致数据规模的膨胀和放大,需要周期性进行压缩。同时,Hudi数据的可见性依赖于Flink计算引擎的CheckPoint间隔设置,在写入操作和压缩操作的双重压力下,为了避免压缩操作与checkpoint的相互阻碍,可以采用离线压缩模式,提升作业的稳定性。
此外,针对各表不同的数据量,实时数仓会针对实时处理作业的运行CPU、内存进行调整,以满足接入作业运行需求;为了保障后续的数据血缘追踪,采用Hive MetaStore作为技术元数据的存储。
2.流批数据模型加工
实时数据通过实时入湖集中接入数据湖后,将转换成流批一体的数据格式,支持流批方式的读取和加工,针对实时数据模型构建过程中的数据依赖特点,实时数仓在数据资产模型的加工能力支持上有不同的侧重点。
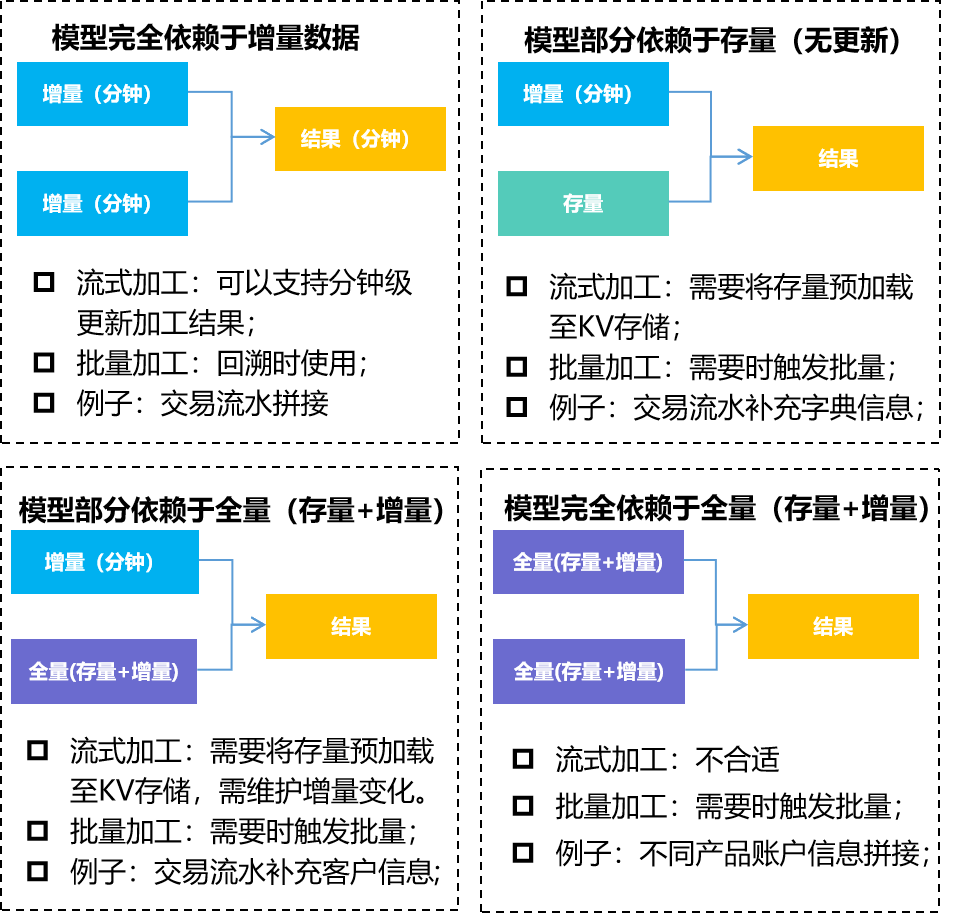
情形一:数据模型完全依赖于增量数据:增量数据均可以实时入仓,并完成后续链路的实时流转,得到分钟级结果;
情形二:数据模型部分依赖于存量(无变化)数据:对于全量数据无变化的依赖数据,可以将存量数据进行加速(缓存至Redis/Hbase等),实现分钟级模型生成,但对存量数据的管理要求很高。
情形三:数据模型部分依赖于全量(存量+增量)数据:对于全量数据缓慢变化的依赖数据,可以将存量数据进行加速(缓存至Redis/Hbase等),并实时维护数据变化,实现分钟级模型生成,但对全量数据的管理要求很高。
情形四:数据模型完全依赖于全量(存量+增量)数据:分钟级就绪,需要时触发批量调度执行,适用于批量模式;
此外,结合农行数据模型的特点,实时数仓对明细类实时数据、主档类实时数据的处理策略有所不同。
① 明细类实时数据
对于明细类交易数据,数据前后关联度较低,可以采用流式写入、流式读取的方式进行增量处理。
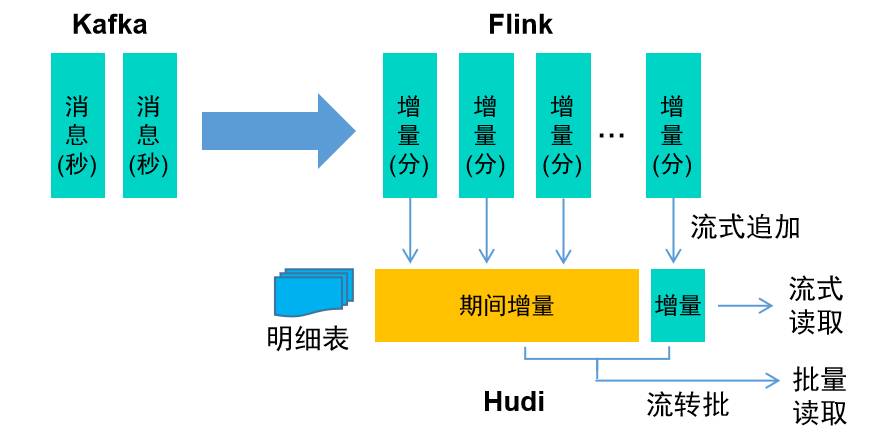
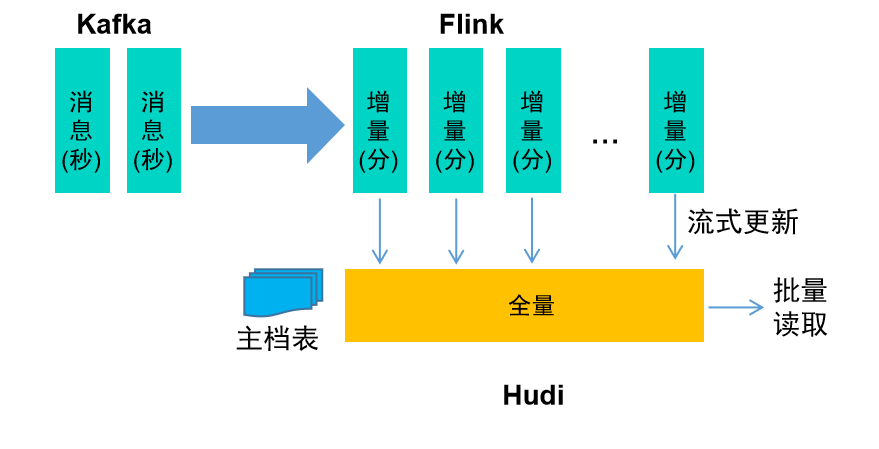
② 主档类实时数据
对于主档类数据,数据需要考虑存量和增量的关系,而存量数据往往数据量比较大,无法直接进行关联处理,可以采用流式更新、批量读取的模式,及时准备好全量数据,实现模型的即时加工。
3.维度数据服务
为提升数据加工时效,实时数据模型对常用的基础维度进行提前补齐,在满足吞吐量等情况下,实现实时数据扩维,以空间换取时间,为数据分组汇总等提供基础数据准备。例如:主档类等具有存量数据的模型,可维护在Hbase、Redis等KV存储引擎中,基于Ad hoc查找的方式实现数据的拼接处理,实现加工链路提速,不会由于主档类数据的加入而导致全链路时效性降低。维度服务作为一种特殊的集成方式,提供全量上线、实时更新和批量增量更新模式。
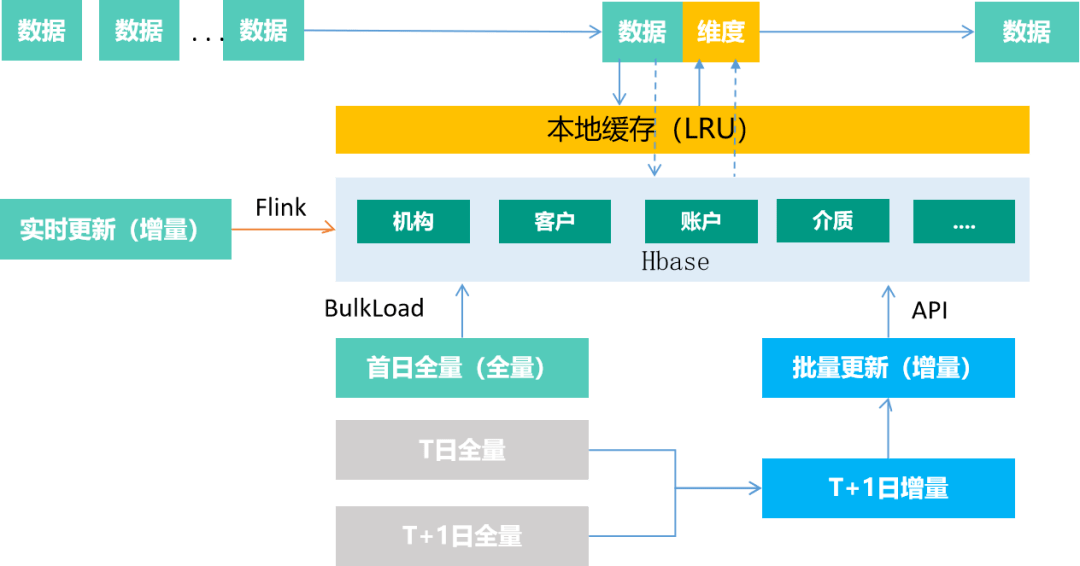
- 维度加载
首次上线时,从大数据平台主库提取完备的全量数据,基于离线加载方式完成维度数据的全量铺底,如基于Bulkload载入全量数据到Hbase。
- 维度更新
维度上线后,为了及时地反映维度信息的变化,维度服务同时会接入维度变化的实时流数据进行更新。
- 维度修正
为了减少离线、实时通道维度数据的偏差放大,维度服务将周期性进行维度数据同步更新修正,实现最新的维度数据和离线维度数据的一致性,避免后续计算口径出现大的偏差。
4.宽表模型加工
宽表是按照“向主流标准靠拢”的方法对数据中台基础数据进行标准化组织整理形成的企业级数据模型表,作为农行新一代大数据模型规范,经过不断迭代和发展,形成了理财、贷款等多种领域宽表。离线宽表模型核心是基于T+N的离线数据处理,因此具有强一致性、高吞吐性等特点,另一方面,为了保证更强的灵活性,离线宽表模型依赖关系错综复杂,流转链路较长。
对于实时宽表而言,直接将离线宽表模型照搬到实时宽表模型成本代价高昂,加之加工环节的相互制约,时效性提升受限,不易实现成本和可行性价值的最大化。在实际业务场景中,很多场景其实并不要求全字段实时化,而是专注于拿到实时的事实数据,因此实时数仓在T-1离线宽表基础上,通过扩增高时效字段等方式进一步满足高时效场景。
四、实时数仓建设探索实践
1.实时理财宽表探索
为探索宽表时效性提升路径,实时数仓以理财宽表为试点,探索实时宽表建设思路。通过梳理整体加工链路,发现当前离线宽表模型具有如下显著特点:
一是增量模式少,增全量模式多,其中交易拼接通用宽表增量与增全量加工比例为(3/25),理财产品历史通用宽表(0/6),理财合约拼接通用宽表(0/43)。
二是模型层次多,加工链路普遍较长,层次普遍在3~7层。
三是模型之间依赖复杂,存在较多关联,模型之间存在大量Join操作,个别模型单次存在11张表关联。
因此,为了实现上述复杂链路的时效性提升,对于明细数据,实时数仓基于Upsert模式实现明细数据的维护,按时间分区分钟级流式写入,提供流式读增量数据,支持了分钟级数据鲜度。
对于主档类数据,由于具有历史数据,实时数仓采用Bulk Insert模式实现存量数据的铺底入湖,通过Hudi全量数据接增量的方式,解决历史数据首次加载,并平滑衔接增量数据的问题。同时,基于流式写分钟级更新数据状态、批量读取模式提供最新全量快照结果。
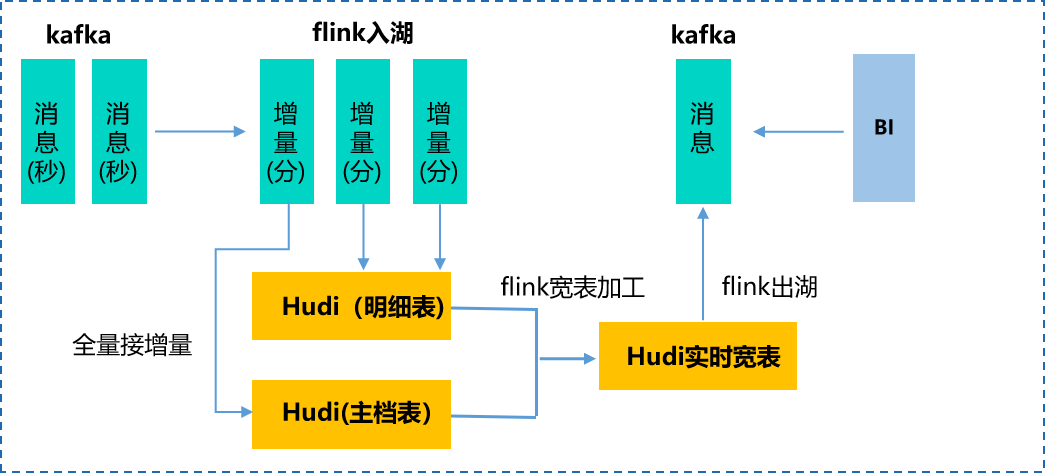
通过对明细、主档类基础数据的实时化处理,可以为宽表模型提供分钟级数据,提升宽表产出时效,支撑重点链路分支分钟级、整体T+0的数据供给时效。
2.实时标签场景实践
针对网金等实时标签建设需求,实时数仓通过个人活期交易、掌银新注册客户等明细模型建设,复用同一共性实时模型数据基础上,拆分跨行交易、个人基金、代发工资3类主题数据,支持标签中心不同类型实时标签构建。此模式按照主题进行管理,进行统一的加工,比如清洗、过滤、扩维等,给下游提供直接可用的数据,避免了数据的重复加工,同时也实现了实时数据的存储回溯,可满足后续实时标签等多场景建设。
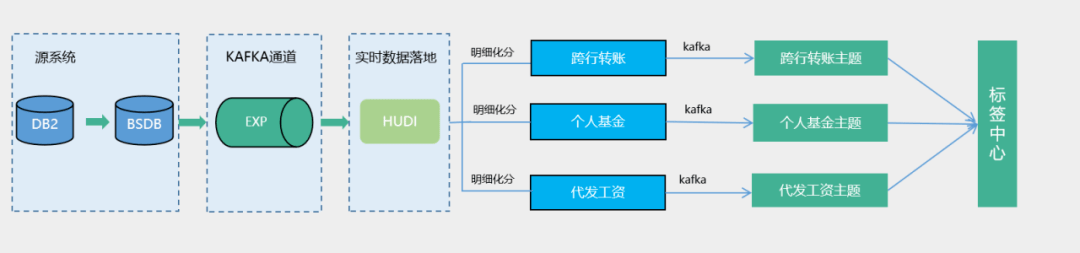
在个人活期交易明细共性模型资产建设实践中,为了满足单表日均亿级的高吞吐入湖集成,实时数仓从Hudi表类型、数据分区、Hudi压缩等措施优化配置,实现高吞吐实时流数据场景下的稳定入湖:
1)Hudi表选型方面,通过长周期疲劳测试发现,此场景下基于COW类型作业会出现较大反压、延迟逐渐放大等情形,为了避免延迟情况,实时数仓基于MOR表的模式,满足高吞吐实时数据的快速入湖;
2)数据分区方面,实时数仓对明细数据模型进行日期分区,考虑到明细类数据插入多、更新少等特点,为了减轻Hudi的Index索引压力,进一步降低索引存效时间;
3)压缩方面,实时数仓考虑到在线压缩对入湖任务造成的不稳定性,采用了离线压缩,通过脚本控制压缩计划的执行,确保不会出现积压的问题。
基于沉淀的共性模型资产,实时数仓先后支撑大额动账实时线索、掌银新客实时标签、代发工资实时标签等多个场景建设。
五、未来展望
湖仓一体实时数仓将数据湖的灵活性、数据多样性、丰富生态与数据仓库的企业级数据分析能力进行了融合,对实时数据模型建设具有重要价值。未来,随着农行数据湖建设,实时数仓将融合数据湖基础底座建设,构建稳定、全面、高扩展性的实时数据基础层,建设和沉淀农行共性实时数据资产,满足不同实时分析应用用数要求。实时数仓基于流批一体数据集成,提升数据加工时效性,促进全行实时分析型应用架构的统一,对实时场景建设支撑等具有重要意义。
1.持续稳定的实时数据供给
实时数仓基于湖的平台化实时集成能力,可以实现对丰富的实时流数据集成,降低各类实时应用实时数据集成建设成本;同时依托数据湖流批一体存储特性,以实现时间旅行等一些新特性,满足可靠性要求等场景,比如某个时间端实时数据的重放处理等等。
2.丰富的实时数据模型资产
实时数仓统筹供给共性的实时数据模型资产,避免了各实时应用端到端的重复加工。比如基于明细层模型,运营可以获取到机构级的汇总结果,营销可以汇总到产品级的结果等等,而各自无需对明细处理,实现实时数据的一口出。
3.开放的多租户能力建设
数据湖仓租户依托数据湖统一存算底座,低成本拎包入住,实现资源申配、实时数据授权、资产发现,利用实时数仓持续实时数据、共性模型供给,并结合数据湖一站式DataOps标准化工艺,无需数据出湖,提升数据加工时效,满足实时应用场景快速落地,实现数据湖价值最大化。
下一步,实时数仓将深度融入到湖仓一体建设,借助现代数据栈,实现统一数据血缘、安全管控、服务共享等,助力农业银行企业级实时数据应用生态发展。
作者丨钟新斌、李志伟、李萌、刘一阳
来源丨公众号:我们的开心(ID:abc_kx)
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn
直播预告丨MySQL 5.7停服倒计时,数据库迁移替代如何布局?
2023年10月月底,MySQL 5.7 将达到其生命周期的终点(EOL,End of Life)。这意味着 Oracle 将不再为 MySQL 5.7 提供官方更新、错误修复或安全补丁。
因此,升级迁移、保障系统安全等,成为了各方产业不得不面对的重点问题,是选择8.0版本、还是另辟蹊径、或是按兵不动?为此,dbaplus社群邀请到新浪微博资深数据库工程师-杨尚刚、Airwallex(空中云汇)资深DB架构师-赵飞祥在云上汇聚,和大家探索MySQL 5.7停服的应对方案及未来规划。
- 观看方式:线上直播间/dbaplus社群视频号
- 时间:10月26日周四晚8点
- 直播地址:z-mz.cn/7U4o7

最新活动丨XCOPS智能运维管理人年会

报名地址:bagevent.com/event/8385364?bag_track=SH