清华团队研发光电融合芯片,推动构建生态友好的AI计算框架
日前,清华戴琼海院士团队与乔飞副研究员团队再迎芯片新成果,他们造出一款名为 ACCEL 的光电融合芯片。该芯片的系统级算力和能效,实测达到高性能工业级 GPU 的 3000 余倍,能效的 4000000 余倍,具备超高算力、超低功耗的特点。
ACCEL 芯片光学部分的加工最小线宽仅采用百纳米级,而电路部分仅采用 180nm 互补金属氧化物半导体(CMOS,Complementary Metal Oxide Semiconductor)工艺,已经比 7nm 制程的 GPU 取得了多个数量级的性能提升。
研究人员表示:“形象来说,如果原本的电量可支持现有高性能芯片工作一小时,那么相同的电量供给下 ACCEL 芯片可以工作五百多年。”
 图 | 部分团队成员合影(来源:资料图)
图 | 部分团队成员合影(来源:资料图)
论文中的实验演示表明,该芯片的成功研制证明了光子计算在诸多 AI 任务中的优越性(即光子霸权),也为解决摩尔定律增速放缓、构建生态能源友好的大规模 AI 计算框架开辟了新路径。
 图 | ACCEL 芯片(来源:课题组)
图 | ACCEL 芯片(来源:课题组)
在论文中,研究人员用“All-analog Chip Combining Electronics and Light”来描述这款光电融合芯片的特征。这句英文的首字母简称为 ACCEL,恰好是“加速”的含义。
当前,人类正处于算力需求爆炸式增长的时代,超高性能的计算架构有着大量用武之地。研究人员非常希望能将 ACCEL 芯片快速用于实践之中。
目前,他们正在基于 ACCEL 芯片的光电计算框架,开展一系列应用探索例如自动驾驶、野外监测、物联网传感器网络、计算机视觉等。
目前,他们已经开展了将超高速图像计算,用于光纤通信中的信号编解码和误码纠错的探索,有望将光纤通信端到端信号处理的时延降低四个数量级。
一旦计算时间从三小时变成三秒钟,很多日常生活应用和科学计算任务将会发生质的变化。
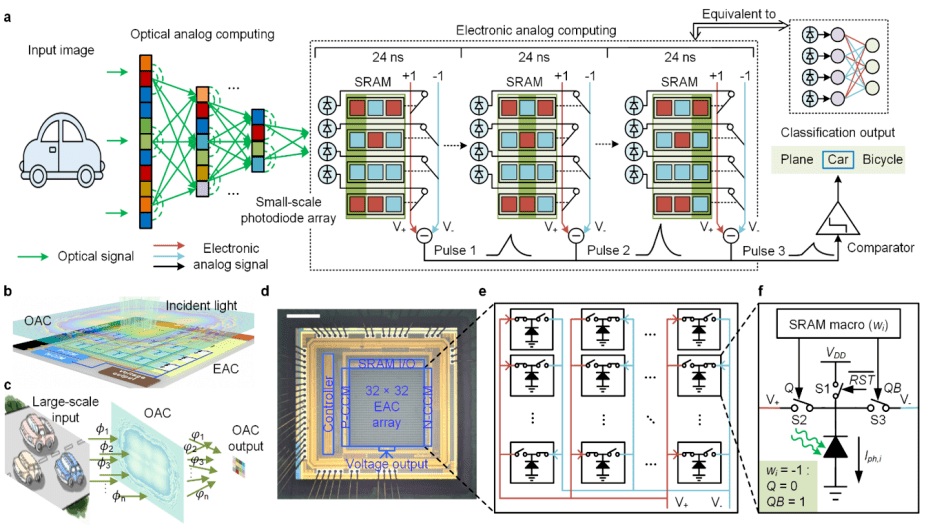 图 | 光电计算芯片 ACCEL 的计算原理和芯片架构(来源:Nature)
图 | 光电计算芯片 ACCEL 的计算原理和芯片架构(来源:Nature)
据介绍,ACCEL 芯片通过融合光域计算和模拟域电计算,来实现神经网络的计算。在光域之中,ACCEL 芯片通过一个多层光学衍射神经网络,针对所输入的高分辨率图像,以光速来进行特征提取和数据降维。
衍射网络的输出,则由一个光电二极管阵列加以接收,并通过光电效应转换成模拟电流信号。通过这种光域处理,可以极大地减小数据维度,从而降低光电转换的规模。
其中,每一个光电二极管所产生的光电流,会根据电网络的权重参数流入相应的计算结点之中,并基于基尔霍夫定律实现模拟域的电计算。
这时,通过光电二极管这一超高速、低功耗的光电接口,光网络和电网络完成连接,让光电融合计算系统实现直接、高效的集成。
那么,在自动驾驶等视觉任务中,ACCEL 芯片的泛化能力如何?泛化能力,通常指一个模型对于新样本、新场景的适应能力。
ACCEL 不仅在不同测试集上表现出很好的泛化能力,在不同工况下也具备优秀的泛化性。比如,同样是用于交通场景的计算,如果出现极弱光、超高帧率等场景,相比单独光计算或电计算,ACCEL 芯片在抗噪声训练算法之下表现出极好的鲁棒性。
此外,现有光计算系统,常常针对特定的专一任务而设计,这导致其应用范围受到限制。而 ACCEL 芯片融合光域计算和模拟域电计算,可以轻松实现重构。
当针对特定任务来设计并制备出来 ACCEL 芯片之后,借助电信号域的易编程性,ACCEL 芯片能够重新训练电网络的参数,从而适用于不同的任务,而几乎不影响最终准确率。
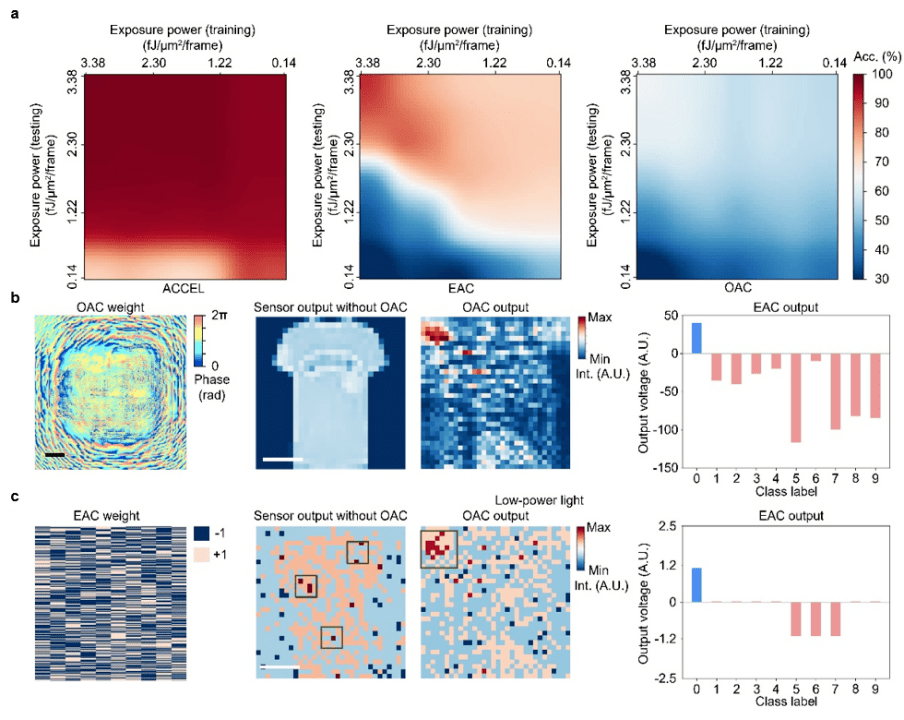 图 | 光电计算芯片 ACCEL 在不同任务和光强下的性能(来源:Nature)
图 | 光电计算芯片 ACCEL 在不同任务和光强下的性能(来源:Nature)

光芯片,有何不同?
相比传统电子芯片,光芯片使用光子来完成相关计算。与传统的电子芯片相比,它并不是用电作为载体来完成数字信号处理,而是通过光在传播和相互作用之中的信息变化来进行计算。
比如在物理学史上著名的杨氏双缝实验中,相干光经过带有两条狭缝的挡板之后,会在后面的探测板上得到明暗相间的条纹。如果把相干平行光看做输入,探测板上的图案看做输出,上述实验就可以简单抽象理解为:挡板对输入光进行了调控,并通过光在挡板和探测面之间的传播,实现了对于输入光信号的处理。
对于现有光计算来说,许多思想都和上述过程类似。即通过精细调控光传播的过程,改变接收位置处的光相位、光振幅、光偏振等物理属性,从而实现光域的计算和信号处理。
光计算芯片的优势在于光子的高速度、低耗能和大带宽,这能为大规模并行计算和高速数据传输提供极具潜力的解决方案。
与此同时,在大量视觉任务及日常生活场景中,原始信号本身就是光信号。使用传统解决方案,需要在传感器拍摄之后,再使用电子芯片进行处理,这会增加光电转换、存储、以及计算的步骤。相比之下,利用光直接进行计算,是一种更自然、更高效的方式。

光芯片,有何不足?
近年来,面对摩尔定律增速放缓和失效危机,光计算作为一种新型计算范式,得到了广泛关注并被寄予厚望。相比目前的电子器件,通过在光域之中直接对原始视觉信息进行处理,让光计算在速度和能效上得以提高几个数量级。然而,目前的光计算系统面临着非线性实现复杂、光电接口耗能等国际难题,导致不少科研工作评估的高性能优势难以落地并实现应用。
基于此,该团队便将课题初衷瞄准攻克当前光计算领域存在的瓶颈,让光计算的超高性能从实验室走到日常生活。

光芯片,如何完善?
为解决上述国际难题,本次研究首次提出了深度融合的光计算和模拟电计算,建立起一种全模拟的芯片计算框架。
为了克服现有光计算系统的痛点,研究人员把目光转向同为模拟计算的电域模拟计算:它借助基尔霍夫电压电流定律、电荷守恒定律等基本的物理规律实现计算。而光信号通过光电效应转换成模拟电信号时,存在着本征的非线性关系。
基于此,他们提出了新的计算范式:ACCEL 将用于大规模提取视觉特征的衍射神经网络和基于基尔霍夫定律的纯模拟电子计算,集成在同一枚芯片框架内。借此绕过模拟数字转换器速度、精度与功耗相互制约的物理瓶颈,从而在一枚芯片之内就能突破大规模计算单元集成、高效非线性、高速光电接口等三大关键瓶颈。在保证高任务性能的同时,还实现超高的计算能效和计算速度。
 图 | ACCEL 有望用于电子设备超低功耗人脸唤醒示意动图(来源:清华大学)
图 | ACCEL 有望用于电子设备超低功耗人脸唤醒示意动图(来源:清华大学)

一场线上会议,诞生一篇Nature 论文
在本次成果的对应论文中,通讯作者多达四位,他们来自不同的团队。这要从 2020 年的一次线上会议说起,当时清华大学电子系乔飞副研究员听取了该校吴嘉敏助理教授关于光计算的报告。
之后,两者所在课题组开展的讨论中,便萌生了这样一个想法:既然同为模拟计算领域,那么是否可以通过深度合作,共同解决领域内的瓶颈问题?
很快他们定下了这项课题。随后,先是开展理论建模和仿真验证,针对衍射光网络的计算模型、光电效应的非线性模型模拟、以及电网络的计算模型,开展了物理推导、物理仿真和芯片设计。
后来在实际流片后和芯片实测中,为了克服实际系统部署中所存在的误差累积和噪声,他们对这些非理想因素进行建模,借此开发出一套系统性修正算法,以此来应对弱光噪声、对齐、加工误差等非理想因素。借此实现了与仿真结果符合度较高的实验准确率。
此后,他们又对芯片系统级的能效和算力加以评估。实测结果显示,ACCEL 芯片在系统级算力和能效上,分别比目前高性能的商用工业级 GPU 高出千余倍和百万余倍。
为了确保如此惊人数据的可靠性,研究人员做了尤为扎实的工作来进行实测和验证。
他们不仅实测了 ACCEL 芯片端到端系统级的耗能数据和时延数据,还进一步提出了等效算力的概念。直接从准确率的角度来衡量计算效果,从而能够摒除不同物理建模方式的影响。
真正做到即便在复杂数据集之上,也能达到和数字卷积神经网络相同的准确率,同时将端到端系统级的耗时降低千倍、耗能降低百万倍。打消了业内人士对光计算算力“有效性”的顾虑。
最终,相关论文以《用于高速视觉任务的全模拟光电子芯片》(All-analog photoelectronic chip for high-speed vision tasks)为题发在 Nature[1],博士生陈一彤、博士生麦麦提·那扎买提、许晗博士是共同一作,清华大学戴琼海院士、方璐副教授、乔飞副研究员、吴嘉敏助理教授担任共同通讯作者。
 图 | 相关论文(来源:Nature)
图 | 相关论文(来源:Nature)
后续,他们将研究规模更大、算力更强的模拟域光电融合系统,这需要在算法层面和硬件层面,开展更高层次的联合设计优化。
另外,以大语言模型为基础,基于新型 AI 算法的高效硬件计算平台,也是非常值得研究的方向之一。
毋容置疑,硬件算力的提升是引领当今 AI 浪潮的重要引擎之一。研究人员认为,基于全模拟光电融合计算的框架,有着非常好的应用前景。
要想进一步拓展应用范围,就需要构建从软件到硬件的生态环境。而一个完善的生态环境,则需要由学界和业界协同打造,因此他们非常期待业界可以在该方向上部署相关业务,让前沿学术成果能够加速转化成为产品,完成高效计算平台范式的进一步跨越。
参考资料:
1.Chen, Y. et al. All-analog photoelectronic chip for high-speed vision tasks. Nature https://doi.org/10.1038/s41586-023-06558-8 (2023).