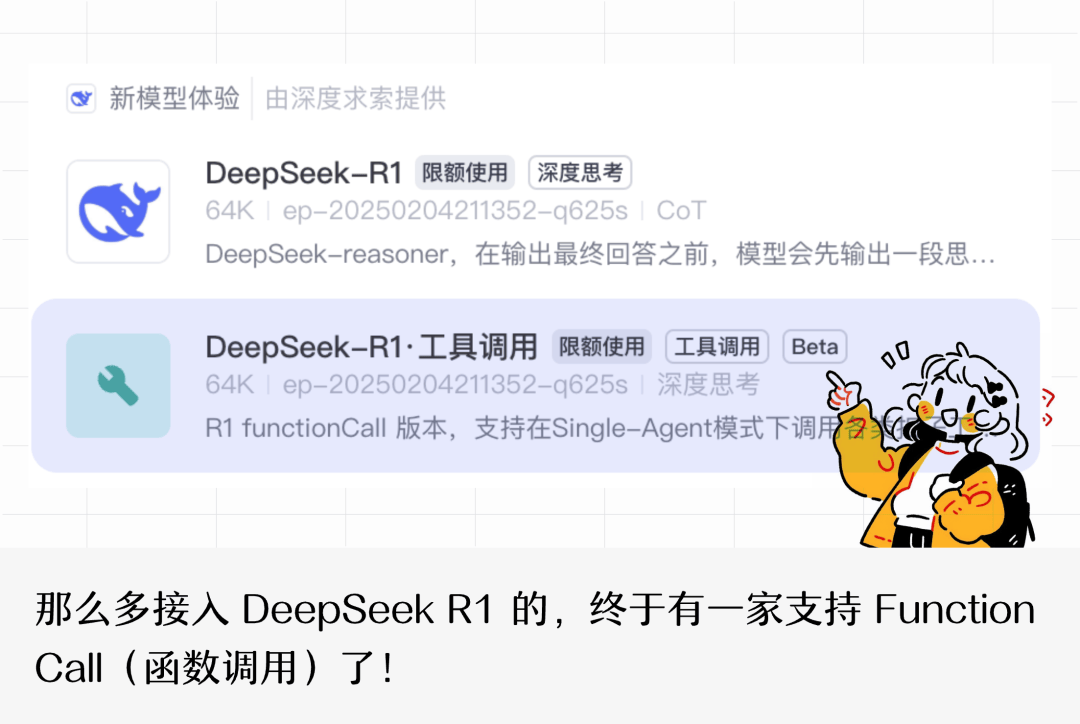
那么多接入 DeepSeek 的,终于有一家支持 Function Call 了!!!
内容丨特工少女
编辑丨特工小鹏 特工十五
众所周知,目前 DeepSeek R1 有一个很大的痛点是不支持 Function Call 的。GitHub 上有许多开发者都表达了这一诉求。

https://github.com/deepseek-ai/DeepSeek-R1/issues/9
而就在特工们参加大聪明(@赛博禅心,知名 AI 博主)的一个小聚会之后的凌晨时分,我们发现 扣子悄悄上线了支持 Function Call 版的 R1!
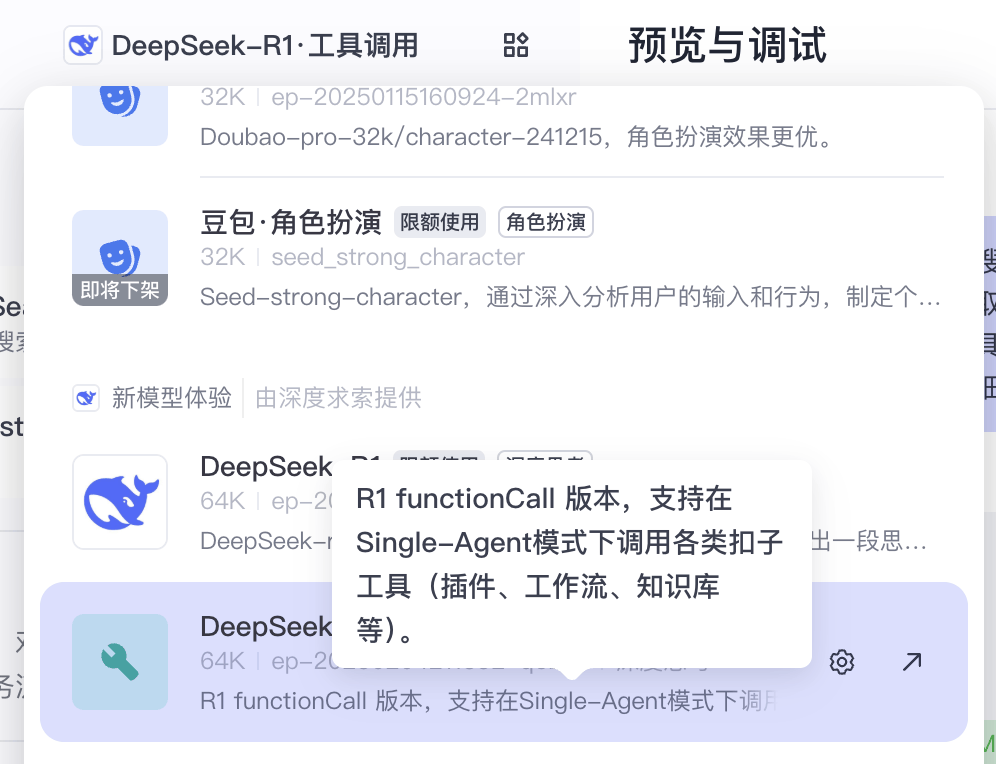
啥是 FunctionCall(函数调用)呢?
Function Call 本质上是让 LLM 成为一个更智能的“操作员”,通过标准化的接口来调用外部工具和服务,从而扩展其能力边界。
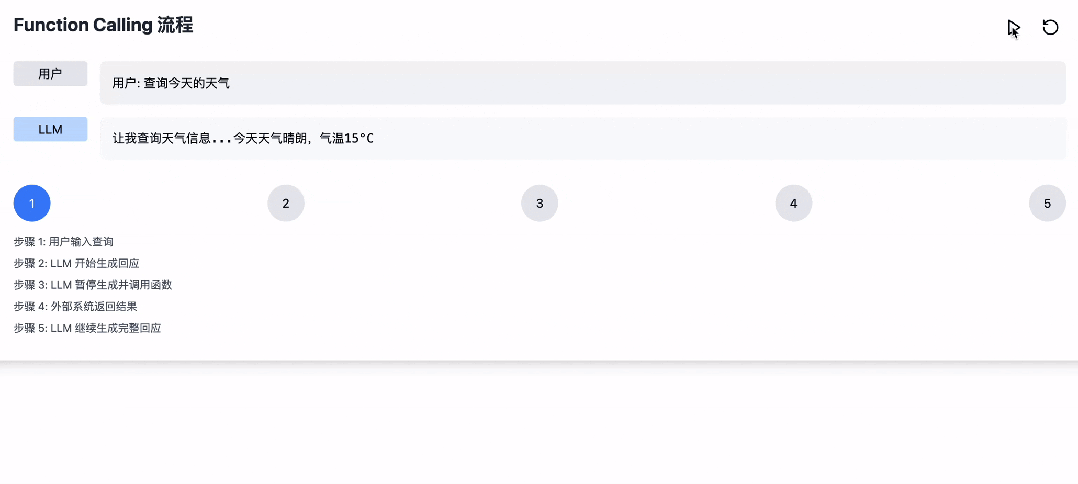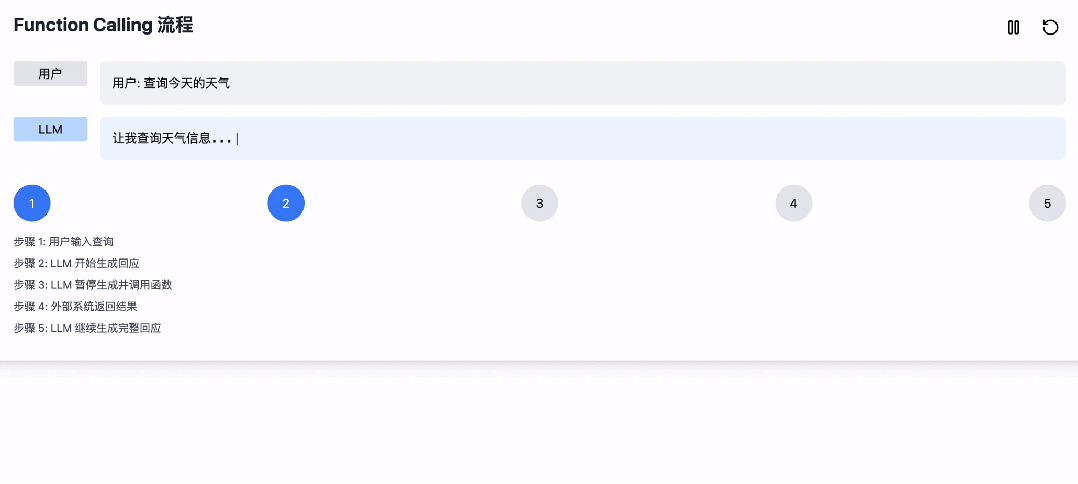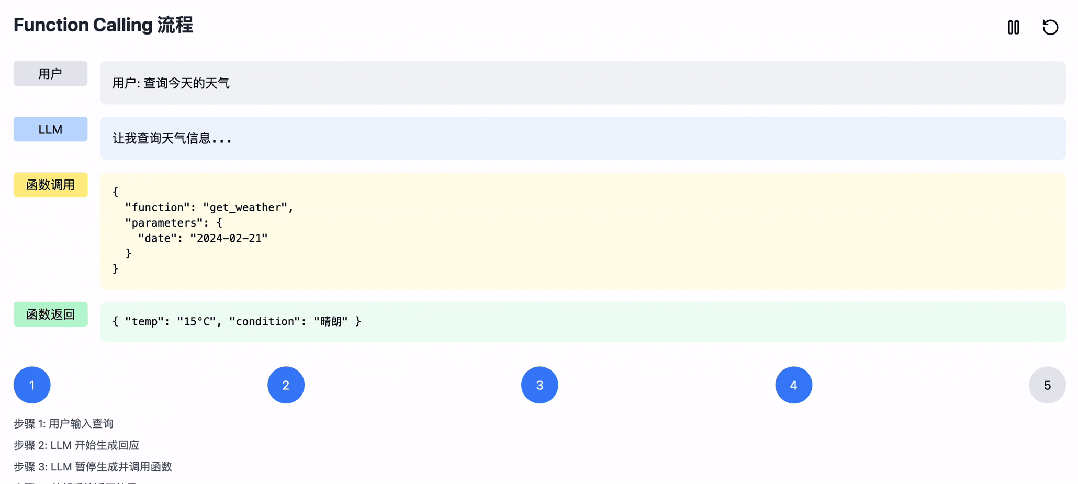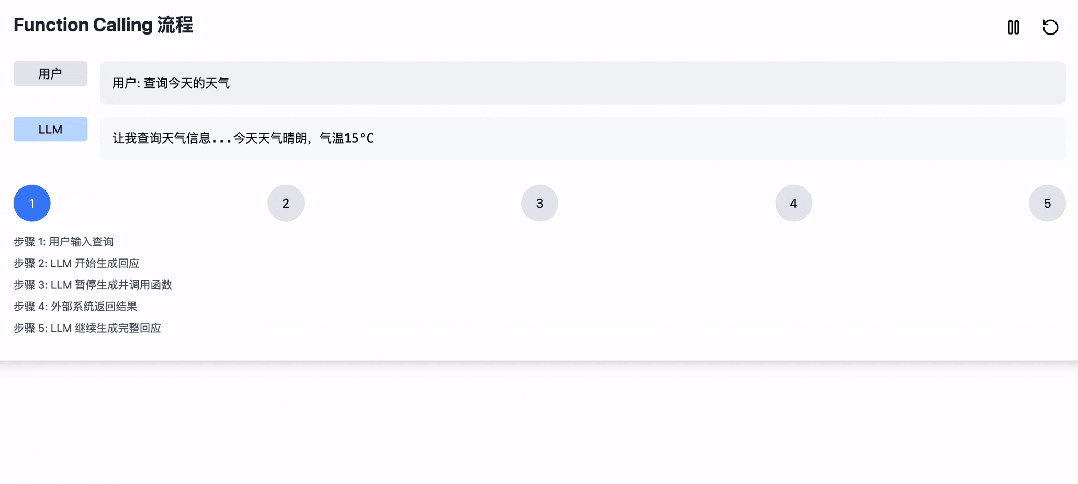
那么大模型是怎么实现 Function Call 的呢,其大概流程是这样的:
1. 用户输入;
2. LLM开始生成回应,直到意识到需要工具调用时;
3. 暂停原有 Token 生成,开始生成函数调用的参数;
4. 外部系统截获函数参数,执行后返回结果;
5. LLM 基于返回结果和前文,继续生成完整回应。
为了方便更好的理解,我们基于 Claude 生成了一个演示动画。
那么 Function Call 对 LLM 来说的价值是什么呢?我们把 LLM 当做数字员工来类比,问题就变成了如何让 LLM 这个数字员工做好任务,以及为什么 Function Call 能帮他做好任务。
作为一个数字员工,在接受到老板提供的任务后,为了让其更好的工作,数字员工需要具备以下能力:
1. 基本的认知基座,认知基座决定了数字员工的处理思路和逻辑。
2. 外部信息的补充,若是缺少了必要的信息,即便是再强的员工也只能是巧妇难为无米之炊。
3. 规约,通过规范员工的行为以及成果展示,让老板或下一个员工更好的接手工作。
有些时候,我们会发现 LLM 这个数字员工给出的结果是有幻觉的,本质就是上面三个部分存在问题。认知基座的缺陷会导致逻辑推理不合理,幻觉也会且总会来自于缺少外部信息的补充。
就像老板常常认为员工已经知道,但员工其实不知道一样,亦或者是员工知道的内容是过时的。这恰恰对应了我们认为模型已经知道,但模型实际上在预训练过程中缺少相关数据,以及模型知道的是在预训练时的旧知识,但到当下已经发生改变,比如物价等。
这里额外提到一个的来自特工的好朋友,清华系开源智能体框架 Eko,对 Function Call 的使用非常灵性。其大概原理是有一个规划层和执行层。规划层对整个任务进行规划,以 Function Call 的方式自动生成工作流,并反馈到执行层,而执行层则是一个个小的智能体,以 Function Call 的形式执行具体任务。
而作为推理模型的 R1 若在 Function Call 的能力稳定后,相信其能在类似框架下展现非常强的能力!
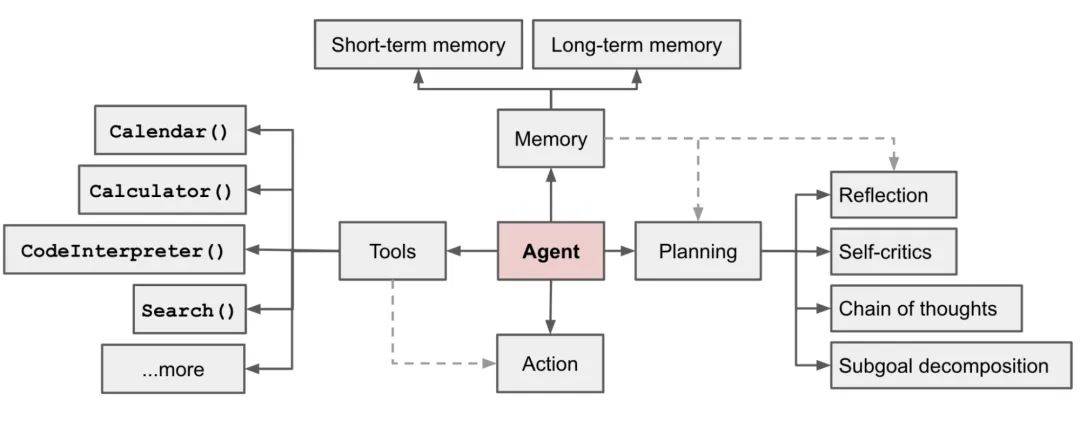
业内都说 2025 都是 AIAgent 元年,而 Deepseek R1 的爆火又为这 2025 年的 AI 开了好头。根据经典 Agent 公式可以明确的是,工具调用是 Agent 的基石。
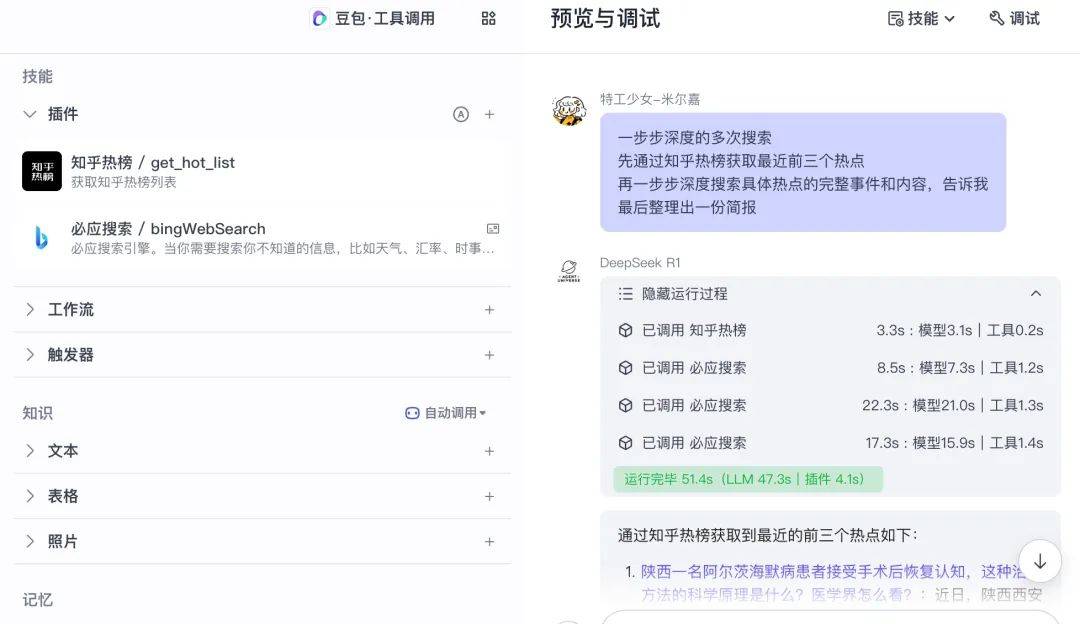
而字节率先将 DeepSeek 支持了 Function Call。现在,模型会自己思考判断是否该调用插件,该调用哪个插件。
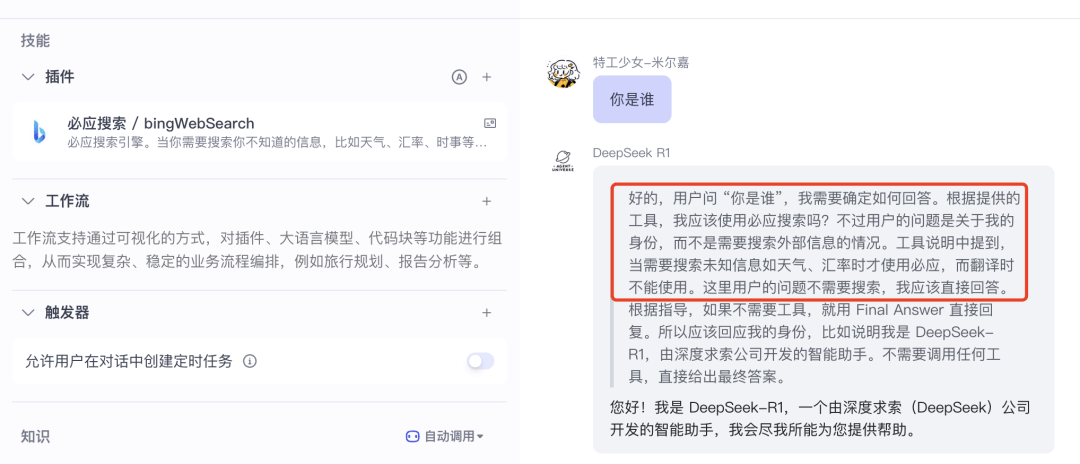
比如我在这里添加了联网搜索插件,但提出了一个无需调用该插件的问题,于是模型在思考过程中判断出无需调用,给出了回复。
再比如,我让模型“查询 B站上的十个热搜,然后做一个思维导图”,模型便主动判断并输入给插件正确的参数。
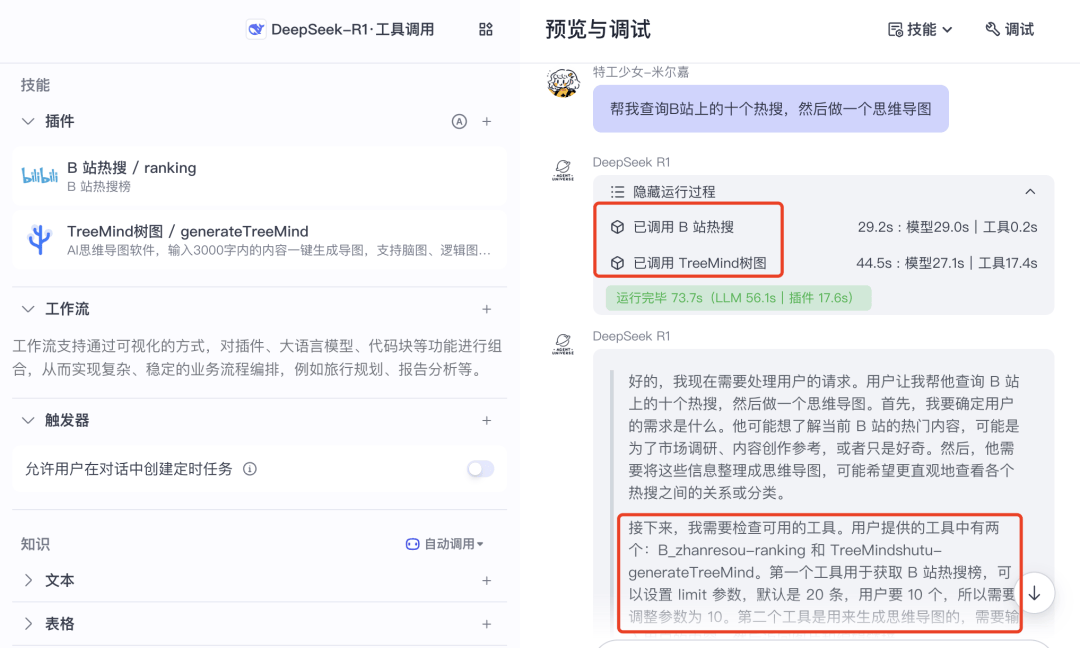
先执行了 A 插件,后执行了 B 插件,最终得到了正确的回复。
不过,体验下来,当下的工具调用版 R1 还存在一些偶发的小问题,包括:
1. 不知道何时应当调用函数,或忘记调用函数;
2. 参数输入不完全准确,未生成具体可被外部解析的 Action,而是输出代码块;
3. 对于较复杂的需求,单次对话里较难重复调用工具。
比如这里我们输入了一个稍显复杂的问题,工具调用版 R1 只调用了两次插件。
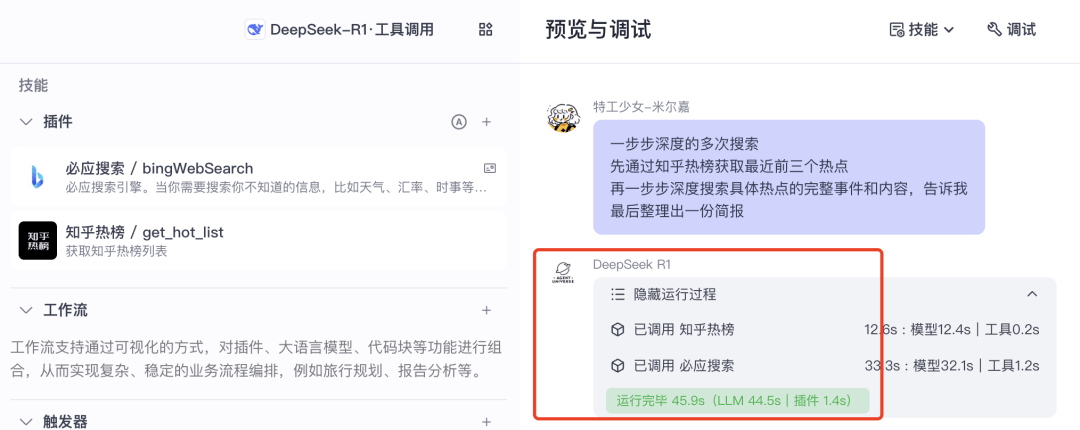
而切换成豆包模型会稳定许多。
最后再同步两个信息:
首先,我们曾在这篇文章中提到“当强化学习的规模化效应叠加在优质基模之上,完全可能催生指数级的能力跃迁。非常期待基于 Qwen2.5-Max 的深度推理模型”。

没想到它真的要来力!
其次,本周五(2.21),也就是今天,特工们来上海参加阶跃星辰发布会了!据说会有超过更新,等我们后续测评和报道!以及,欢迎周末来 GDC 大会与我们面基!